 Після того, как мы с вами познакомились со рядками і символьними масивами в C ++, розглянемо найпоширеніші функції для роботи з ними. Урок буде повністю побудований на практиці. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, як вони влаштовані. Стандартними опціями бібліотеки cstring относятся:
Після того, как мы с вами познакомились со рядками і символьними масивами в C ++, розглянемо найпоширеніші функції для роботи з ними. Урок буде повністю побудований на практиці. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, як вони влаштовані. Стандартними опціями бібліотеки cstring относятся:
- strlen() – подсчитывает длину строки (количество символов без учета \0);
- strcat() – объединяет строки;
- strcpy() – копіює символи одного рядка в іншу;
- strcmp() – порівнює між собою два рядки .
Это конечно не все функции, а только те, які ми розберемо в цій статті.
strlen() (от слова length – длина)
Наша программа, которая подсчитает количество символов в строке:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
Для подсчёта символов в строке неопределённой длины (так как вводит её пользователь), мы применили цикл while – строки 13 – 17. Он перебирает все ячейки массива (все символы строки) поочередно, начиная с нулевой. Коли на якомусь етапі циклу зустрінеться осередокourStr [amountOfSymbol], яка зберігає символ\0, цикл приостановит перебор символов и увеличение счётчика amountOfSymbol.
Так будет выглядеть код, з заміною нашої ділянки коду на функціюstrlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
Як бачите, этот код короче. В нем не пришлось объявлять дополнительные переменные и использовать цикл. В выходном потоке cout ми передали в функцію рядок – strlen(ourStr). Она посчитала длину этой строки и вернула в программу число. Как и в предыдущем коде-аналоге, символ \0 не включен в общее количество символов.
Результат буде і в першій програмі і в другій аналогічний:
 в C++")
strcat() (от слова concatenation – соединение)
Программа, яка в кінець одного рядка, дописывает вторую строку. Другими словами – объединяет две строки.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
За коментарями в коді повинно бути все зрозуміло. Нижче напишемо програму для виконання таких же дій, но с использованием strcat(). В цю функцію ми передамо два аргументи (две строки) – strcat(someText1, someText2); . Функція додасть рядокsomeText2 до рядкаsomeText1. При этом символ ' 0' в кінці someText1буде перезаписан першим символомsomeText2. Так само вона додасть завершальний ' 0'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Реализация объединения двух строк, используя стандартную функцию, заняла одну строчку кода в программе – 14-я строка.
Результат:

На що слід звернути увагу і першому і в другому коді– размер первого символьного массива должен быть достаточным для помещения символов второго массива. Если размер окажется недостаточным – может произойти аварийное завершение программы, так як запис рядка вийде за межі пам'яті, которую занимает первый массив. Наприклад:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
В этом случае, строковая константа“Учите С c нами!” не може бути записана в масивsomeText1. В нём недостаточно места, для такой операции.
Якщо ви використовуєте одну з останніх версій середовища розробки Microsoft Visual Studio, возможно возникновение следующей ошибки: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” Так происходит потому, що вже розроблена нова більш безпечна версія функціїstrcat – цеstrcat_s.
Она заботится о том, чтобы не произошло переполнение буфера (символьного массива, в который производится запись второй строки). Среда предлагает вам использовать новую функцию, вместо устаревшей. Почитать больше об этом можно на сайте msdn. Подобная ошибка может появиться, якщо ви будете застосовувати функціюstrcpy, о которой речь пойдет ниже.
strcpy() (от слова copy – копирование)
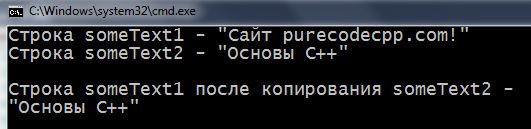
Реализуем копирование одной строки и её вставку на место другой строки.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Застосуємо стандартну функцію бібліотекиcstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Пробуйте компилировать и первую, и вторую программу. Увидите такой результат:
strcmp() (от слова compare – сравнение)
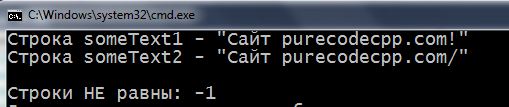
Эта функция устроена так: она сравнивает две Си-строки символ за символом. Если строки идентичны (и по символам и по их количеству) – функция возвращает в программу число 0. Якщо перший рядок довший другий – повертає в програму число 1, а если меньше, те -1. Число -1 повертається і тоді, когда длина строк равна, но символы строк не совпадают.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
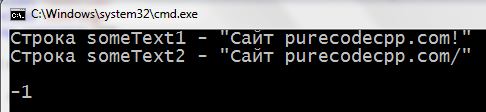
 програма зstrcmp():
програма зstrcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Діліться в соціальних мережах нашими статтями зі своїми знайомими, которые так же изучают основы программирования на языке С .
Є Мільярде штук, які ви пропустили, але дуже докладно описали очевидне…
>> Программа, яка в кінець одного рядка, дописывает вторую строку. Іншими словами - об'єднує два рядки.
І так, і іншими словами – усяк різно, а суть не ясна.
у мене 2 рядки char * під кожну виділено 256 байт.
В першу записано “Здравствуйте”, в другу “світ”.
Я їх поєдную. Скільки байт мені треба? 512 или 10?
Відповідаєте і йдемо далі по тексту :).
Володимир, тема покажчиків в цій статті не піднімалася. Якщо говорити про символьних масивах (Si-strokah) розміром в 256 байт кожен, то після об'єднання рядків “Здравствуйте” і ” світ”, рядок в яку дописали символи world, займатиме 256 байт, як і до об'єднання.
#include#include
using namespace std;
int main()
{
setlocale(LC_ALL, "rus");
char strHello[256] = "hello"; // все ячейки после hello будут содержать символ /0
char strWorld[256] = " world";
strcat(strHello, strWorld);
cout < < strHello << endl << endl; cout << "Размер строки strHello в байтах после объединения = " << sizeof(strHello) << endl; // функция sizeof() возвращает размер в байтах, переданного ей аргумента return 0; }
Рядок strWorld займе осередки рядка strHello, наступні за символами hello (перший символ рядка strWorld "zatret" \0 після символу 'o' рядки strHello).
Працюючи з покажчиками на рядки, звичайно, краще перевиделять необхідну кількість пам'яті для зберігання символів рядків і не займати зайве місце. вийде, що необхідно 12 байт для "Привіт Світ". Все по порядку - дійдемо і до цього :)
P.S. коментарі,код і роз'яснення не для тебе, а для новачків, які будуть читати те про що ми говоримо
Можу я написати
strcat(strHello, strHello)
?
Почему?
Питання дійсно дуже цікавий! Мені раніше не доводилося задуматися над цим. На перший погляд, в цьому записі немає нічого дивного. Але ж не працює ж! :) Помилка свідчить “Буфер занадто малий”. Один мій знайомий (Віталій) відповів мені так на це питання: “в документації написано, що “якщо об'єкти функції перекриваються, її поведінка не визначається.” програміста який так напише засмокче в void )) ” Ну і ще так продовжив: “копіювання йде посимвольний. функція шукає \0 в першому рядку, знаходить, і починає туди посимвольний клеїти другий рядок. АЛЕ! вона буде клеїти поки не знайде \0 якого УЖЕ НЕМАЄ!
Вова, будемо вдячні, якщо ти теж відповіси нам на це питання.
пам'ять то вже виділена
Ну правильно товариш сказав, перший рядок копіює символи зі свого початку в свій кінець, тому зростає нескінченно.
У мане написано:
Рядки не можуть перекриватися, а в dest має бути достатньо місця для розміщення результату.
Реально відбувається переповнення буфера, але чисто випадково це може спрацювати (помилку не вилізе), але програма модифікується як-небудь непередбачене.
Докапаться то я до того, що опис цієї функції в мане займає рядків 6. просто, зрозуміло і все відразу (і про буфери достатнього розміру і про перетин рядків). Ви пишіть сто разів одне і теж різними словами, не знаю навіщо xD.
>> P.S. коментарі,код і роз'яснення не для тебе, а для новачків, які будуть читати те про що ми говоримо.
Ти ж писала статтю про угоди про кодування. Ніби як в деяких з них вказується оптимальну кількість коментарів в коді. До кожної рядку ніхто не пише.
А ті в НЕ indeksiruetsâ Пошуковик (Або я помиляюсь?), тому просто вигідніше опис до коду поміщати після коду, а не всередині.
Ти пишеш, “функції для роботи з рядками в С ++”, реально вони колись лежали в , але в С ++ є , а старі (“сішние”) рядки винесені в (ось там і описані ці всякі strcat, … ). Тобто,. я прочитав заголовок і очікував прочитати про std::string, а тут… (мене обдурили xD).
так в коді немає коментарів в кожному рядку )) там всього їх пара штук. P.S. написаний був для того, щоб ти не подумав ніби я тобі все це пояснюю. Ти ж знаєш – це зрозуміло ))
З приводу заголовка. До назви звичайно можна чіплятися… Тільки якби стаття була про string, її теж не назвеш “функції для роботи з рядками в С ++”. швидше – Методи для роботи з рядками об'єктами класу string.
Як би ти назвав дану статтю? Може і правда краще перейменувати.
Але читаю статтю далі…
Про strcpy ти привела щось типу аналога, т.е. спробувала запив strcpy своїми руками, я вірно розумію?
просто
Чи не точно xD.
У мане (в стандарті мабуть теж) написано що рядки не можуть перекриватися. У gcc начебто перекриваються рядки відпрацьовують нормально, але за стандартом це може бути невизначена поведінка, а значить в іншому компілятор (іншою версією цього ж компілятора) воно може зламатися.
Я вважаю, що по цій темі краще описати типові помилки (з зЬгсру – це переповнення буферу) і способи боротьби.
Я б про вироби мелкософта згадав, strcpy_s типу. Якщо ви пишете код в віжуал студії, то стопудово вам у вікно сипляться попередження про те, що strcpy треба замінити на безпечну версію – strcpy_s. Ось про цю штуку можна написати ІМХО.
подивіться тут
ну про strcpy_s і про strcat_s – це мій був до тебе питання )) виходить тепер, що питання сама собі поставила.
Цікава у тебе манера спілкування:
– просто.
– не зовсім.
+ Мої питання мені ж і ставиш…
Вова. Пропоную спілкуватися так, ніби ми дуже поважаємо один одного )
але в цілому статті стали придатними, код відформатований хоча б одноманітно :). Більш веселих прикладів не вистачає, чи що…
Пишіть ще :)
ну знаєш, ти не на КВН заглянув :)
>> Вова. Пропоную спілкуватися так, ніби ми дуже поважаємо один одного )
“На ви” чи що? )
Про більш правильні назви статей нічого не знаю. Я не любитель мікростатей, я б написав під такою назвою і про Сі-рядки, и про string. Придумав би який-небудь приклад, в який звів би купу строкових функцій, а до самих функцій написав би дуже короткі (otnostrochnиe) коментарі, звів би їх в таблицю. Написав би про переповнення буферів – це вобще типова помилка при роботі з рядками, safe-функції від Мікрософтвера і ще приклад типу… “дан масив рядків, треба злити його в одну велику рядок” – тут би зупинився на оцінці асимптотичної складності – приклад шикарний і оцінка складності не лежить на поверхні.
Я не стільки питання задаю, скільки пропоную теми для наступних статей (або тези до допив поточної).
В будь-якому випадку – спасибі за конструктивну критику та пропозиції! Цікаво з тобою спілкуватися
Про приклад зі злиттям масиву рядків поясню.
у strcat є артефакт, ти ось вірно вже написала, що перед тим як приступити до злиття, він замінює символ . Але щоб його занменіть, його треба знайти. А як його знайти, якщо розмір рядка не відомий? – перебрати послідовно всі елементи рядка.
Якщо ти зливаєш 2 строки – перша довжиною N, друга – M, то буде виконано N + M операцій, т.к. спочатку N операцій для пошуку , а потім M операцій для запису вмісту другого рядка в першу.
хоча, багато програмісти, не заглянувши в документацію очікують M операцій, т.к. про пошук забувають.
відповідно, якщо у нас є масив з K рядків і вийде так, що перший рядок дуже довга, а решта дуже короткі, то складність алгоритму буде не дуже маленькою (хоча, ми ж додає короткі строки до довгої), а близькою до K * тільки, де тільки – сума длинн всіх рядків. Коротше квадратична складність замість лінійної.
А ось в std::string все зовсім інакше, хоча складність залишиться такою ж (приблизно, адже є штуки типу memcpy і вектор може рости ривками) незважаючи на те, що розмір рядків відомий. думайте чому, МБ статтю нову намалюєте.
Пару рядків на захист Автора!
Володимир, звертаюся до вас “Про більш правильні назви статей нічого не знаю” – нічого чіплятися до придуманого назвою, а то виходить – мені не подобається, але не знаю як краще… “я б написав…”, “придумав би…”, ” звів би…” і т. д. і т.п. Але не написав, не придумав, не звели… (якщо я занадто категоричний або глибоко неправий – поділіться, будьте люб'язні посиланням на Вашу статтю на аналогічну тему). А хтось написав, придумав, зробив. А Ви тепер сідіете “весь такий розумний” і критикуєте. Я б теж багато чого хорошого зробив…. У той час як хтось бере і робить! Мені наприклад і статті дуже подобаються і приклади зрозумілі. Виклад значно зрозуміліша ніж у мого нинішнього викладача по С ++ в ВУЗі (ще один комплімент автору). Багато тем освоїв завдяки цьому сайту а не заняттям і конспектами (як і сумно). Автор, спасибі за Вашу працю! Не зупиняйтеся на досягнутому, Ваші старання приносять користь людям!
перший приклад про порівняння 2х рядків у мене не компілюється без
#include але в прикладі він не вказано.
У прикладах в літературі (і набагато більш складних, ніж показано) досить часто необхідні #include не вказуються – вважається, що ви їх впишете самі в необхідній кількості.
саме то, які потрібні #include, може змінюватися в залежності від операційної системи і компілятора … а далеко не у всіх (к счастью) MS VisualStudio як у вас.
А як використовувати повернене функцією strcmp число?
if( 0 == зЬгстр( str1, str2 ) ) /* рядки збігаються * /
else /* не збігаються */
Інші повернені значення (0) означають лексографіческое впорядкування рядків str1 і str2 … але для цього потрібно представляти, що таке лексографіческій порядок.
У передостанньому прикладі не вистачає #include . Кодеблокс послав…