Есть некоторая строка (слово, число), например “home”. Необходимо заполнить этим словом строку (последовательно буквами этого слова) за определённое количество итераций.
Например: базовая строка – “home”, требуемое число символов результата 11, результат: “homehomehom”
В этой задаче главным требованием должно быть: сделать это как можно больше разными способами! (задача то сама по себе совсем элементарная).
Решения:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | #include <cstdint> #include <string> #include <iostream> using namespace std; string rep1(const string& base, int rep) { string ret = ""; for (int i = 0; i < rep; i++) ret += base[i % base.length()]; return ret; } string rep2(const string& base, int rep) { string ret = ""; for (int i = 0; i < rep; i += base.length()) ret += rep - i > base.length() ? base : base.substr(0, rep - i); return ret; } string rep3(const string& base, int rep) { string ret = ""; for (int i = 0; i < rep / base.length(); i++) ret += base; return ret + base.substr(0, rep % base.length()); } string rep4(const string& base, int rep) { char buf[1000]; strcpy_s(buf, base.c_str()); while (strlen(buf) < rep) // удвоить длину memmove(buf + strlen(buf), buf, strlen(buf) + 1); buf[rep] = '\0'; return string(buf); } string rep5(const string& base, int rep) { string ret(base); while (ret.length() < rep) ret += ret; // удвоить длину return ret.erase(rep, ret.length() - rep); } int main() { setlocale(LC_ALL, "rus"); string(*tests[])(const string& base, int rep) = { rep1, rep2, rep3, rep4, rep5, // последовательность тестов }; while (true) { cout << "базовая строка?: "; string word; cin >> word; int rep; cout << "длина результата?: "; cin >> rep; for (int i = 0; i < sizeof(tests) / sizeof(tests[0]); i++) cout << tests[i](word, rep) << endl; } return 0; } |
Вот как это будет выглядеть при исполнении:
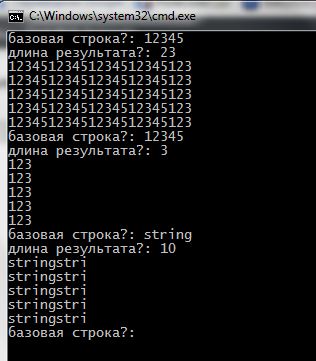
Здесь показано несколько (5) вариантов решения для базовой строки в формате std::string. Но ещё много интересных вариантов может быть записано для строки в формате char[] (такой код будет даже проще для понимания).
P.S. В таком случае ваши функции вариантов (если вы хотите сохранить массив функций-обработчиков) могут иметь прототип:
1 2 3 4 5 | char* rep( const char* base, uint rep ) { static char ret[ 1000 ]; // здесь ваш код! ... return ret.erase( rep, ret.length() - rep ); } |
Предлагайте следующие варианты!
Наилучший по оптимальности из показанных будет rep4, но там выделение буфера (char buf[1000]) сделано с потолка и чисто для иллюстрации, легко его переполнить.
Добавлю ещё 2 вариата в развитие этого способа:
string rep6( const string& base, uint rep ) {
char* buf = (char*)alloca( rep * 2 );
strcpy( buf, base.c_str() );
while( strlen( buf ) < rep )
memmove( buf + strlen( buf ), buf, strlen( buf ) + 1 ); // удвоить длину
buf[ rep ] = '\0';
return string( buf );
}
string rep7( const string& base, uint rep ) {
char buf[ rep * 2 ];
strcpy( buf, base.c_str() );
while( strlen( buf ) < rep )
memmove( buf + strlen( buf ), buf, strlen( buf ) + 1 ); // удвоить длину
buf[ rep ] = '\0';
return string( buf );
}
#include
#include
using namespace std;
int main()
{
int a;
cout<>a;
int const BUFERSIZE=a;
int bufer=0;
string slovo;
cout<>slovo;
do
{for(int i=0;i<slovo.size();i++)
{
if(bufer<BUFERSIZE)
cout<<slovo[i];
bufer++;
}
}while(bufer < BUFERSIZE);
return 0;
}