В этой статье я опишу методику работы с двунаправленным списком в классическом его варианте. Ввод списка, вывод и сортировку по разнообразным условиям и полям элементов списка. Не буду вдаваться в теорию списков – перейду к описанию того, что необходимо сделать для решения данной задачи, и по ходу дела опишу почему именно так я организовал работу.
Для построения списка нам понадобятся две структуры: Одна – поля элемента списка. Вторая – сам элемент списка с якорями, которые будут связывать элементы между собой.
Первая структура может выглядеть так:
1 2 3 4 5 | struct TRecord { //В котором есть некоторые поля int x; string s; }; |
Это структура данных списка. В ней должны содержаться поля, которые непосредственно к самому списку (вернее к его структуре ) отношения не имеют, зато хранят информацию. Эта запись – контейнер (назовем ее так).
Вторая запись:
1 2 3 4 | struct TList { TRecord Rec; TList *Next, *Prev; } |
Она уже призвана хранить в себе элемент контейнера, в который мы упакуем данные, и поля для связи с элементами-соседями в списке.
Для чего понадобился такой разворот на две структуры? Так будет удобнее производить сортировку. В обычных условиях список сортируется путем перенаправления его полей-якорей на другие элементы (Next и Prev в данном примере). Т.е. сами данные, как были в памяти так в той же ячейке (ячейках) и остаются, а меняются только указатели на соседей. И это конечно хорошо и правильно, но сложно. Чем выше сложность, тем больше вероятность нарваться на баг в программе. Поэтому стоит упростить программу, чтобы можно было не якоря менять, а данные местами (как обычно это делается в сортировке массивов к примеру). Поэтому целесообразнее данные выделить в отдельный блок-структуру, чтоб перетягивать их одним оператором, а не таскать каждое поле отдельно. Ниже вы увидите что имеется ввиду.
Для работы со списком нужны переменные головы списка и, по необходимости, хвоста:
1 | TList *Head=0, *Last=0; |
И вот так уже будет выглядеть процедура наполнения списка:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | void Add(int x, string s){ //Создадим элемент TList *r = new TList; //Наполним его данными r->Rec.x = x; r->Rec.s = s; //Обнулим указатели на соседей чтоб список //не содержал мусора r->Next = 0; r->Prev = 0; //Если этот элемент не первый - сцепим его //и предыдущий элемент if (Last) { Last->Next = r; r->Prev = Last; } //И если это голова - запомним ее if (!Head) Head = r; // После чего дадим понять программе //что созданный элемент теперь будет хвостиком Last = r; } |
Ее тоже можно было разделить на две: Первая создавала бы элемент, вторая наполняла бы его контейнер полезными данными, но это уже по вкусу.
Не забываем о процедуре освобождения списка. Оставлять мусор в памяти – дурной тон, даже если умная операционка сама умеет чиститься:
1 2 3 4 5 6 7 8 9 10 11 12 | void Clear(){ //Если он вообще существует if (!Head) return; //В цикле пройдем последовательно по элементам for (Last = Head->Next; Last; Last = Last->Next){ //Освобождая их соседей сзади. //т.е. убирая предыдущие delete Last->Prev; Head = Last; } delete Head; } |
Процедура вывода:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | void Write(){ //Так же в цикле for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout << Last->Rec.x; } cout << endl; for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout.setf(ios_base::right); cout << Last->Rec.s; }; cout << endl; cout << endl; } |
Такая большая она из-за “марафета”. Красивый вывод на экран – достаточно важная опциональность программы. Поэтому ширину для элементов и табличный вид стоит соблюсти.
Теперь переходим к самому интересному – сортировке списка. Процедуру сортировки я разбил на две части, убрав из нее условия проверки, которые анализируют нужно ли сортируемые элементы продвигать по списку в зависимости от условия. Сама же процедура сортировки выглядит так:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | void Sort(string FieldName, string Direct){ //Сортировкой пузырьком пройдемся по элементам списка for (TList *i = Head; i; i = i->Next){ for (TList *j = Head; j; j = j->Next){ //В зависимости от указанного направления if (Condition(Direct, FieldName, i->Rec, j->Rec)){ //Произведем обмен контейнера списка TRecord r = i->Rec; i->Rec = j->Rec; j->Rec = r; } } } } |
В нее договоримся передавать опции сортировки: Имя поля, которое подлежит сортировке, и направление сортировки (asc – по возрастанию или desc – по убыванию).
В процедуре применена сортировка пузырьком, как самая ходовая. В двойном цикле происходит вызов функции-анализатора, которая должна ответить сортировке, нужно ли менять местами сортируемые элементы или нет. Видите, убрав условия сортировки, я упростил код самой процедуры сортировки. Даже если нужно будет добавлять какие-то еще условия или поля, саму сортировку уже не придется трогать.
Функция анализатор выглядит так:
1 2 3 4 5 6 7 | bool Condition(string Direct, string FieldName, TRecord a, TRecord b){ return (Direct == "asc" && FieldName == "x" && a.x > b.x) || (Direct == "desc" && FieldName == "x" && a.x < b.x) || (Direct == "asc" && FieldName == "s" && a.s < b.s) || (Direct == "desc" && FieldName == "s" && a.s > b.s) ; } |
Она выполняет 4 условия:
- Если asc – по возрастанию, и сортируемое поле – х:
- Если desc – по убыванию, и поле то же
- Если asc – по возрастанию, но сортируется второе поле, строковое
- Если desc – по убыванию с строковым полем
В каждом из условий соответственно производится сравнение “больше” или “меньше” в зависимости от заданных параметров сортировки. Таким образом эта функция отвечает процедуре сортировки, как ей поступать с элементами. В целом это и есть весь алгоритм сортировки двунаправленного списка.
Собираем описанное выше в одну программу и дописываем функцию main():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 | #include<iostream> #include<string> using namespace std; struct TRecord { //В котором есть некоторые поля int x; string s; }; struct TList { TRecord Rec; TList *Next, *Prev; }; TList *Head; TList *Last; void Add(int x, string s){ //Создадим элемент TList *r = new TList; //Наполним его данными r->Rec.x = x; r->Rec.s = s; //Обнулим указатели на соседей чтоб список //не содержал мусора r->Next = 0; r->Prev = 0; //Если этот элемент не первый - сцепим его //и предидущий элемент if (Last) { Last->Next = r; r->Prev = Last; } //И если это голова - запомним ее if (!Head) Head = r; // После чего дадим понять программе //что чозданный элемент теперь будет хвостиком Last = r; } void Clear(){ //Если он вообще существует if (!Head) return; //В цикле пройдем последовательно по элементам for (Last = Head->Next; Last; Last = Last->Next){ //Освобождая их соседей сзади. //т.е. убирая предидущие delete Last->Prev; Head = Last; } delete Head; } void Write(){ //Так же в цикле for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout << Last->Rec.x; } cout << endl; for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout.setf(ios_base::right); cout << Last->Rec.s; }; cout << endl; cout << endl; } bool Condition(string Direct, string FieldName, TRecord a, TRecord b){ return (Direct == "asc" && FieldName == "x" && a.x > b.x) || (Direct == "desc" && FieldName == "x" && a.x < b.x) || (Direct == "asc" && FieldName == "s" && a.s < b.s) || (Direct == "desc" && FieldName == "s" && a.s > b.s) ; } void Sort(string FieldName, string Direct){ //Сортировкой пузырьком пройдемся по элементам списка for (TList *i = Head; i; i = i->Next){ for (TList *j = Head; j; j = j->Next){ //В зависимости от указанного направления if (Condition(Direct, FieldName, i->Rec, j->Rec)){ //Произведем обмен контейнера списка TRecord r = i->Rec; i->Rec = j->Rec; j->Rec = r; } } } } int main() { setlocale(LC_ALL, "Russian"); //Наполняем список Add(rand() % 100, "Иванов"); Add(rand() % 100, "Петров"); Add(rand() % 100, "Сидоров"); Add(rand() % 100, "Бородач"); //Крутим список так и сяк cout << "Исходный список:" << endl; Write(); cout << "x (A->Z):" << endl; Sort("x", "asc"); Write(); cout << "x (Z->A):" << endl; Sort("x", "desc"); Write(); cout << "s (A->Z):" << endl; Sort("s", "asc"); Write(); cout << "s (Z->A):" << endl; Sort("s", "desc"); Write(); //Освобождаем список Clear(); cin.get(); return 0; } |
Обратите внимание: Я словами указываю, как сортировать список, по какому полю и в каком порядке.
Результат:

О втором методе сортировки списка путем перезацепления якорей можете почитать на programmersforum
По просьбе коллег по сайту (которые конечно же правильно заметили) стоит хотя бы вкратце упомянуть о прелестях C++ и STL. Имею ввиду класс list, который собственно олицетворяет списки (двунаправленные). Посыл простой: Все, что нужно для работы со списком уже сделали. По хорошему, программисту, работающему со списками, конечно же стоит в бытовых случаях избирать для работы STL.
Опишу небольшой код с применением этого контейнера, как альтернатива тому, что описано выше:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <list> #include <string> #include <iostream> using namespace std; //Опишем структуру данных элемента struct TData{ int i; string name; }; //Функцию, которая будет выступать "предикатом" //в сортировке bool Condition(TData &a, TData &b){ return a.i<b.i; } int main() { //"Создадим" переменку списка, тип елементов укажем //в <>. В данном случае это список TData list<TData> l; //Постепенно добавим элементы в конец списка TData d; d.i = 1; d.name = "1"; l.push_back(d); d; d.i = 20; d.name = "2"; l.push_back(d); d; d.i = 36; d.name = "3"; l.push_back(d); d; d.i = 4; d.name = "4"; l.push_back(d); /*И вызовем функцию сортировки, передав ей предикат Предикат - функция, принимающая два параметра, которые в ней будут сравниваться. */ l.sort(Condition); //После сортировки выведем список на экран использовав //специально предназначенный для прохода по его элементам //итератор list<TData>::iterator it; for (it = l.begin(); it != l.end(); it++){ d = *it; cout << d.i << '\t' << d.name << endl; } l.clear(); cin.get(); return 0; } |
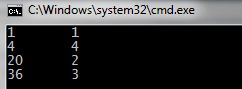
Если задача позволяет использовать STL – используйте. Решение окажется надежнее и не будет траты времени на изобретения своего механизма хранения списков.
Выбор из этих двух методов стоит делать в зависимости от количества полезных данных, что вводятся в элемент списка. Если это пара десятка полей с числами или небольшими строками, то самый простой способ, как раз – перемещение контейнера с полезными данными (как здесь). Если же элементы списка имеют огромный размер, то быстрее будет выполняться методика перестановки якорей (изменения Last и Next для перезацепления элемента к другому элементу). В любом случае выбор за программистом.
It’s cool but this your algorithm replaced only data fields in nodes. If you gotta do great job you need replace pointers:
void Sort(Node *&Top, Node *&End) {
if (Top && Top->next) {
Node *current = Top;
Node *prev = nullptr;
Node *tmp = nullptr;
bool flag = false;
for (int i = 0; i next) {
tmp = current->next;
if (current->data > tmp->data) {
flag = true;
current->next = tmp->next;
tmp->next = current;
if (prev)
prev->next = tmp;
tmp->prev = prev;
prev = tmp;
if (current == Top)
Top = tmp;
if (!current->next)
End = current;
}// The if end
else {
prev = current;
current = current->next;
}
}// The while end
if (!flag)
break;
else {
current = Top;
prev = nullptr;
flag = false;
}
}// The for end
}
else
cout << "\nNo entries for sorting\n";
}
Azizjan, почитай внимательнее статью. Ссылку на метод, где данные остаются на своем месте я давал в предложении
“О втором методе сортировки списка путем перезацепления якорей можете почитать на programmersforum”
Уверен что новичкам полезно знать и такой и такой метод.
Есть код готовый?