Все предыдущие типы контейнеров (рассмотренные подробно или упоминавшиеся: vector, list, deque) — это последовательные коллекции, в которых элементы последовательно упорядочены один за другим, а отличаются они между собой способом доступа к элементам.
Другую большую категорию контейнеров составляют так называемые ассоциативные контейнеры, которые представляют собой, фактически, таблицы, поиск значений в которых производится по некоторым ключам.
Но прежде чем детализировать ассоциативные контейнеры, обратим внимание на такой шаблонный класс (в составе STL) как pair<>. Это достаточно простая конструкция. Каждый такой объект представляет связную пару полей first и second. При построении таблиц (в STL или в ваших собственных классах) эти поля могут представлять как ключ, так и значение. Но не станем спешить — шаблонный класс pair<> и сам по себе может представлять интерес безотносительно к контейнерам.
Мы можем, например, определить класс представления точек 2D плоскости для решения широкого класса геометрических задач (файл point.h):
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | #include <iostream> using namespace std; // класс point наследуется от класса pair<float, float> class point : protected pair<float, float> { public: // конструкторы point(void) { first = second = 0; } point(float x, float y) { first = x; second = y; } point operator -(const point& sub) { point p(*this); p.first -= sub.first; p.second -= sub.second; return p; // разница по координатам } float abs(void) { return sqrt(first * first + second * second); return 0; } inline friend ostream& operator <<(ostream& out, const point& obj) { return out << "<" << obj.first << "," << obj.second << ">"; return out; } }; int main(int argc, char *argv[]) { point p1(1, 3), p2(3, 1); cout << "the distance between two points " << p1 << " & " << p2 << " is " << (p1 - p2).abs() << endl; } |
point p(*this); означает, что создаётся новая переменная (объект) класса point, и вызывается её копирующий конструктор. Для инициализации берётся значение текущего объекта *this – то на что указывает указатель this. Т.е. новая переменная point p создаётся, как копия текущего объекта. В остальном вам всё должно быть понятно.
Результат:

Теперь, когда мы видим, что из себя представляет шаблонный класс pair<>, мы можем перейти к обзору того, что представляют собой основные ассоциативные контейнеры STL.
В отличие от рассмотренных ранее последовательных контейнеров, где местоположение элемента определяется его положением среди других элементов, в ассоциативных контейнерах элементы хранятся как пара (pair<>) <ключ, значение>. Для поиска значения элемента требуется его ключ поиска, который может быть самых разнообразных типов.
Примечание: Можно считать, что в массиве или векторе ключом поиска является индекс, который всегда имеет целочисленное значение. По аналогии, шаблонный тип таблицы (хэш-таблицы) map<>, с которого мы начнём обзор ассоциативных типов, можно рассматривать, как массив или вектор (для простоты понимания ). Он может индексироваться любым (но всегда только одним) произвольным типом ключа, типа: title[ ‘a’ ], или pay[ “Иванов” ].
Одним из наиболее часто используемых ассоциативных контейнеров STL является map<> — таблица, массив пар <ключ, значение>, в котором поиск элемента производится по ключу.
Ключ может иметь любой сложный тип, при условии, что для этого типа существует операция сравнения (меньше-больше), или такая операция реализуется пользователем и указывается при создании таблицы. Для иллюстрации простейшего применения map<> воспользуемся уже рассмотренным раньше примером с базой данных студентов факультета:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #include <iostream> #include <string> #include <map> using namespace std; struct data1 { int group, age, scholarship; // группа, возраст, стипендия data1(void) { group = age = scholarship = 0; } data1(int group, int age, int scholarship = 0) : group(group), age(age), scholarship(scholarship) {} data1(const data1& d) : group(d.group), age(d.age), scholarship(d.scholarship) {} inline friend ostream& operator <<(ostream& out, const data1& obj) { return out << "[" << obj.group << " : " << obj.age << " : " << obj.scholarship << " ]"; } }; // это и есть наша таблица, журнал деканата, ФИО здесь - ключ: typedef map< string, data1 > faculty; int main(void) { setlocale(LC_ALL, "rus"); faculty filology; // заполняем поочерёдно 3 записи в журнал: filology.insert(pair< string, data1 >("Сидоров С.С.", data1(13, 19, 1500))); filology.insert(pair< string, data1 >("Иванов И.И.", data1(13, 20))); filology.insert(pair< string, data1 >("Петров П.П.", data1(11, 21))); // вывод на экран ФИО и учётных данных for (auto i = filology.begin(); i != filology.end(); i++) { cout << i->first << " : " << i->second << endl; } data1 d1(filology["Иванов И.И."]); data1 d2 = filology["Иванов И.И."]; cout << d2 << endl; } |
Результат:
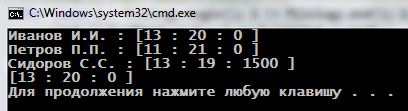
Даже такой поверхностный пример (пока мы не углубились в детали ассоциативных контейнеров) позволяет увидеть и сделать некоторые выводы:
Элементы, помещаемые в таблицу, размещены не в порядке их помещения (как было с vector или list), а в отсортированном порядке по значению ключа (ФИО);
Вот почему для типа данных ключа должна либо существовать операция сравнения, либо она должна быть создана пользователем;
Для поиска (по ключу) в ассоциативных контейнерах используется не последовательный перебор всех элементов, а в высшей степени эффективные и сложные алгоритмы, отработанные за годы (и даже десятилетия) существования STL . Обычно для реализации map<> используется техника красно-чёрных деревьев … но детали этого не принципиальны. Важным выводом из этого факта должно стать то, что поиск в ассоциативных контейнерах весьма быстр, и он гораздо лучше, чем если бы вы попытались его реализовывать вручную.
Автор, ты мудак, школота сраная. На что я потратил время?
Примеры кода громоздкие, новичку суть уловить сложновато!
Такое чувство, что комментарии здесь пишут умственно отсталые.
map, set, multiset, multimap – реализованы НЕ через хеш таблицы, а через красно-черные деревья, по крайней мере так в gcc. Через хэш таблицы реализованы контейнеры с префиксом unordered_. Очень странно что автор с 40-летним стажем и таким внушительным списком достижений об этом не знает.