Следующую, очень нужную и очень мощную группу алгоритмов STL представляют обобщённые численные алгоритмы (заголовочный файл <numeric>). Это не какие-то особые вычислительные методы, как можно подумать исходя из названия. Это алгоритмы, позволяющие применять общеизвестные библиотечные или свои собственные вычислительные функции ко всей совокупности элементов контейнера.
А поскольку так, то и вызываются они подобно всем другим алгоритмам STL. Используются такие обобщённые алгоритмы, главным образом в математических вычислениях применительно к контейнерам, содержащим числовые элементы. Но это совсем не обязательно. И если вас не интересуют численные вычисления (например из области цифровой обработки сигналов), то вы можете просто безболезненно пропустить эту часть изложения…
Перечислим представленные STL обобщённые численные алгоритмы: iota (создание монотонно возрастающей последовательности), accumulate (накопление), inner_product (скалярное произведение), partial_sum (частичная сумма), adjacent_difference (смежная разность).
Иллюстрацию работы лучше всего провести на самом используемом и интуитивно понятном алгоритме accumulate. Этот алгоритм редуцирует (уменьшает размерность) контейнера с накоплением значений. В частности, для простых числовых значений он сворачивает vector<> или list<> до одиночного скалярного результирующего значения.
Алгоритм accumulate (как, впрочем, и большинство других) имеет 2 синтаксические формы:
1 2 3 4 5 | template <class InputIterator, class T> T accumulate( InputIterator first, InputIterator last, T init ); template <class InputIterator, class T, class BinaryOperation> T accumulate( InputIterator first, InputIterator last, T init, BinaryOperation binary_op ); |
В 1-й форме (она менее интересная) алгоритм суммирует значения элементов контейнера. Не забываем при этом, что для типа string, например, операция ‘+‘ означает конкатенацию, склеивание). Во 2-й форме алгоритм накапливает результат бинарной операции (функции 2-х переменных), применяемой к накапливаемому значению (аккумулятору) и поочерёдно к каждому элементу контейнера.
Непонятно? Это мощная техника, и сейчас всё станет понятно из примера…
В математической статистике находят применение несколько видов среднего значения для числовой последовательности:
Среднее арифметическое:
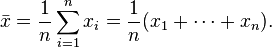
Среднее геометрическое:
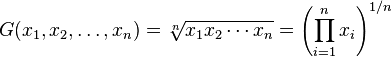
Среднее гармоническое:
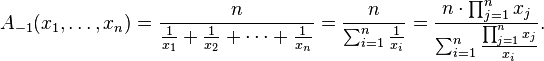
Среднее квадратическое:
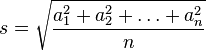
Не станем углубляться в смысл каждого из вариантов. Мы сделаем приложение, которое подсчитывает эти средние и ещё некоторые характеристики (дисперсию, средне квадратичное отклонение) для вводимой числовой последовательности. Входную последовательность вводим либо с терминала, либо перенаправлением из предварительно подготовленного файла данных:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | #include <iostream> #include <vector> #include <sstream> #include <numeric> #include <cmath> using namespace std; double amean; // среднее арифметическое (значение) double disp(double acc, double seq) { // накопление квадратов отклонений seq -= amean; return acc + seq * seq; } double mul(double acc, double seq) { // произведение элементов return acc * seq; } double garm(double acc, double seq) { // сумма обратных значений return acc + 1. / seq; } double sqr(double acc, double seq) { // сумма квадратов элементов return acc + seq * seq; } int main(void) { setlocale(LC_ALL, "rus"); string s; getline(cin, s); // читаем входную строку istringstream ist(s); // поток для чтения мз строки double d; vector<double> ser; // числовой массив while (ist >> d) ser.push_back(d); // поэлементное чтение чисел в массив int n = ser.size(); auto b = ser.begin(), e = ser.end(); amean = accumulate(b, e, 0.) / n; // сумма элементов double variance = accumulate(b, e, 0., disp) / n, deviation = sqrt(variance), gmean = exp(log(accumulate(b, e, 1., mul)) / n), rmean = n / accumulate(b, e, 0., garm), smean = sqrt(accumulate(b, e, 0., sqr) / n); cout << "ср.ариф.=" << amean << " ср.геом.=" << gmean << " ср.гарм.=" << rmean << " ср.квад.=" << smean << endl << "дисперсия=" << variance << " СКО=" << deviation << endl; } |
Как легко видеть, каждая из записанных выше сложных математических формул вычисляется всего лишь в одну строку, используя технику обобщённых алгоритмов:

Здесь мы можем наблюдать известное соотношение, которое подтверждает корректность наших вычислений. Заключается оно в том, что для любой последовательности чисел среднее арифметическое больше или равно среднего геометрического, которое, в свою очередь, больше или равно среднего гармонического. Причём равенство в этих утверждениях достигается только если все члены числовой последовательности равны между собой:
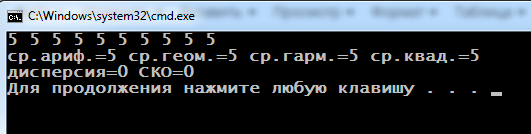
Возвратимся к изучению кода. Первый вызов алгоритма accumulate( b, e, 0. ) демонстрирует 1-ю форму использования: значения контейнера суммируются с начальным значением 0.0.
Предупреждение!: Запись точки в константе начального значения, указывающая, что это вещественное значение — принципиально важна. Без этого код будет компилироваться даже без предупреждений, но выполняться с совершенно неверными и крайне сложно толкуемыми результатами! Это связано с тем, что алгоритмы определены как template, и тип 3-го параметра определит для какого типа данных будут задействованы внутренние операции при накоплении.
Все остальные (4 штуки) вызовы accumulate() используют 2-ю форму вызова – передают 4-м параметром функцию накопления. Как видно из примеров, она принимает параметрами текущее накопленное значение и очередной элемент контейнера. А возвращает результат накапливающей операции. Для наглядности, все накапливающие функции записаны в примере в простом и ясном виде. На практике, чтобы избежать зависимости от типа обрабатываемых данных, их также обычно записывают, как шаблонные функции. Тогда это может выглядеть так:
1 2 3 4 5 6 7 8 9 10 | template <typename T> T mul( T& acc, const T& seq ) { return acc * seq; } int main( void ) { vector<long> ser = { 1, 2, 3, 4, 5, 6, 7, 8, 9 }; cout << accumulate( ser.begin(), ser.end(), 1L, mul<long> ) << endl; } $ ./numb3 362880 |
Наконец, обратите внимание, если не обратили до сих пор, что при накоплении сумм мы используем начальное значение 0 (3-й параметр accumulate() ), а при накоплении произведений, естественно, 1, с соответствующим типом данных.
Всем привет!
Сегодня заглянул на онлайн сайты, где раньше смотрел, удивленно нашел что они не работают, то есть их фильмы не транслируют вообще, типо в вашей стране видео запрещенно!
Теперь фильмы не глянуть онлайн по всюду фильмы удалены, что опять назад на торренты?
Не … просто “типо”: руки растут из задницы :-(