Алгоритм сортировки массива “пузырьковая сортировка” рассматривается практически во всех учебниках по программированию на С . Его легко понять начинающим. Он наглядный и очень простой.
На практиці цей алгоритм майже ніхто не використовує, так как он медлительный и есть более быстрые и усовершенствованные алгоритмы. Мы также разберем его потому, что сортировка “пузырьком” – это основа некоторых более эффективных алгоритмов, которые будут изложены в следующих статьях. Это“быстрая” сортировка, “пирамидальная” сортировка и “шейкерная” сортировка.
Как работает “пузырьковая” сортировка? Припустимо у нас є невідсортованемассив чисел из 5-ти элементов и нам предстоит разместить значения по возрастанию. Для наочності, на малюнку зобразимо цей масив вертикально “Исходный массив”.
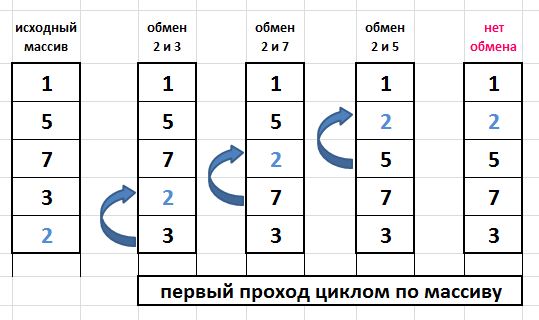
алгоритм сортування “пузырьком” состоит в повторении проходов по массиву с помощью вложенных циклов. При каждом проходе по массиву сравниваются между собой пары “соседних” элементов. Якщо числа якийсь із порівнюваних пар розташовані в неправильному порядку – происходит обмен (перезапись) значень осередків масиву.
Образно говоря в нашем примере 2 “легче” чем 3 – поэтому обмен есть, далее 2 “легче” чем 7 – снова обмен и т.д. При порівнянні нульового і першого елемента на нашому малюнку обміну немає, так как 2 “тяжелее” ніж 1. Таким чином більш “легкое” значение, как пузырек в воде, піднімається вгору до потрібної позиції. Ось чому у цього алгоритму таку назву.
Рассмотрим алгоритм сортировки “пузырьком” в работе:
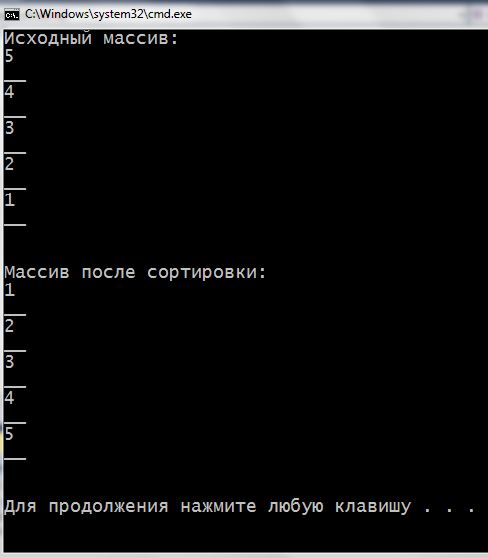
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 | #include <iostream> using namespace std; // прототип функции, которая выполнит сортировку "пузырьком" void bubbleSort(int arrForSort[], const int SIZE); void main() { setlocale(LC_ALL, "rus"); const int SIZE = 5; int arr[SIZE]; cout << "Исходный массив:\n"; for (int i = 0; i < SIZE; i++) { arr[i] = SIZE - i; // заполняем значениями по убыванию cout << arr[i] << "\n__\n"; } cout << "\n\n"; bubbleSort(arr, SIZE); // передаем в функцию для сортировки cout << "Массив после сортировки:\n"; for (int i = 0; i < SIZE; i++) { cout << arr[i] << "\n__\n"; } cout << "\n\n"; } void bubbleSort(int arrForSort[], const int SIZE) { int buff = 0; // для временного хранения значения, при перезаписи for (int i = 0; i < SIZE - 1; i++) // { // вложенный цикл проходит от четвертого элемента // до первого, находит с помощью if самое "легкое" значение, // сравнивая соседние пары элементов, // и поднимает его в нулевую ячейку массива for (int j = SIZE - 1; j > i; j--) { if (arrForSort[j] < arrForSort[j - 1]) { buff = arrForSort[j - 1]; arrForSort[j - 1] = arrForSort[j]; arrForSort[j] = buff; } } // далее значение i увеличивается на 1 // и внутренний цикл будет перебирать элементы // от четвертого до второго. Таким образом поднимет самое // "легкое" значение из оставшихся в первую ячейку и т.д. } } |
Внимательно разобрав данный пример с подробными комментариями, вам повинно бути все зрозуміло. Результат на экране такой:
Дополнить можно следующим: после того, как внутренний цикл отработает один раз, минимальное значение массива будет занимать нулевую ячейку. Поэтому при повторном проходе, чергове мінімальне значення з решти треба буде розмістити в наступній комірці (i + 1).
Таким чином немає необхідності порівнювати між собою всі елементи масиву знову і кількість оброблюваних значень зменшується на 1. при сортуванні “пузырьком” необходимо пройти SIZE – 1 итераций внешнего цикла, так як порівнювати один елемент з самим собою – смысла нет.
Не будем забывать то, о чем мы говорили в самом начале – алгоритм “пузырьковой” сортировки малоэффективен и медлителен. Если у нас есть частично отсортированный массив и необходимо переместить в начало только одно значение, он все равно будет проходить все итерации циклов. То есть производить сравнение уже отсортированных значений массива, хотя этого уже можно и не делать.
Давайте немного улучшим эту ситуацию. Добавим в код еще одну переменную-“флажок”, которая будет давать знать, произошел ли обмен значений на данной внешнего цикла итерации или нет. Перед тем, как войти во внутренний цикл, “флажок” будет сбрасываться в 0.
Если обмен значениями в этом цикле случится – “флажку” будет присвоено значение 1, если нет – то он останется равным 0. В последнем случае (если “флажок” равен 0) – обменов не было и массив полностью отсортирован. Поэтому программе можно досрочно выйти из циклов, чтобы не тратить время попусту на последующие ненужные сравнения.
Рассмотрите следующий пример:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 | #include <iostream> using namespace std; void bubbleSort(int arrForSort[], const int SIZE); int main() { setlocale(LC_ALL, "rus"); const int SIZE = 5; int arr[SIZE] = {3, 4, 2, 5, 6}; cout << "Исходный массив:\n"; for (int i = 0; i < SIZE; i++) { cout << arr[i] << "\n__\n"; } cout << "\n\n"; bubbleSort(arr, SIZE); cout << "Массив после сортировки:\n"; for (int i = 0; i < SIZE; i++) { cout << arr[i] << "\n__\n"; } cout << "\n\n"; return 0; } void bubbleSort(int arrForSort[], const int SIZE) { int buff = 0; int f; // "флаг" for (int i = 0; i < SIZE - 1; i++) { f = 0; for (int j = SIZE - 1; j > i; j--) { if (arrForSort[j] < arrForSort[j - 1]) { buff = arrForSort[j - 1]; arrForSort[j - 1] = arrForSort[j]; arrForSort[j] = buff; /* если хоть одна пара значений былы расположена неправильно то есть условие if - верно, то присваиваем флагу значение 1*/ f = 1; } } // если массив отсортирован и замен не было // то есть f осталось равным 0 - прерываем цикл if (f == 0) break; // для себя показываем количество проходов по массиву вложенным циклом cout << i + 1 << "!!! \n"; } cout << endl; } |
Видим такую картину после запуска:
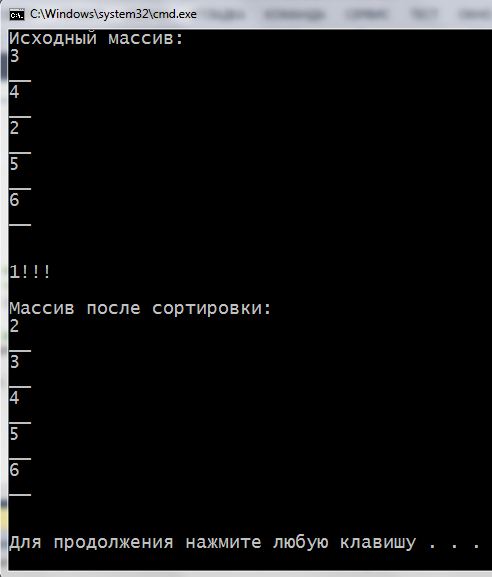
Видно что программа прошла вложенным циклом по массиву 1 раз, переместила значение 2 в нужное место и завершила работу. А вот, что будет на экране, если закомментировать все строки кода, где есть переменная-“флажок”:

Программа вхолостую 4 рази “гоняла” по массиву, хотя значение 2 перемещено в нужную ячейку еще при первом проходе вложенным циклом.
В сети есть прикольное видео (автор: алгоритміці). В нем представлена “пузырьковая” сортировка в усовершенствованном варианте (когда отсортированные элементы массива уже не сравниваются между собой). Єдине – в наших примерах сравнение значений начиналось с последнего элемента. А в запропонованому відео – від нульового до останнього. Посмотрите и увидите, як елементи переміщаються в масиві на потрібні місця :)
Доброго дня.
Допоможіть, будь ласка розібратися в методі, ламаю голову не можу зрозуміти принцип двох вкладених циклів.
є код:
#include
#include
using namespace std;
int main()
{
setlocale(LC_ALL, “російський”);
INT НУМС[10];
int a,b,T;
int size;
розмір = 10; // Кількість сортируемих елементів.
// Розміщуємо масив випадкові числа.
for(т = 0; T<size; т ++) НУМС[T] = rand();
// Відображаємо вихідний масив.
cout << "Исходный массив:\n ";
for(т = 0; T<size; т ++) cout << НУМС[T] << ' ';
cout << '\n';
//Реалізація алгоритму бульбашкового сортування.
for(а = 1; а =; b–) {
if(НУМС[б-1] > НУМС[b]) { // Якщо значення елементів масиву
// розташовані не по порядку,
// то міняємо їх місцями.
т = НУМС[б-1];
НУМС[б-1] = НУМС[b];
НУМС[b] = т;
}
}
// Відображаємо відсортований масив.
cout << "\n Отсортированный массив:\n ";
for(т = 0; T<size; т ++) cout << НУМС[T] << ' ';
system("pause");
return 0;
}
цікавить:
for(а = 1; а =; b–) {
if(НУМС[б-1] > НУМС[b]) { // Якщо значення елементів масиву
// розташовані не по порядку,
// то міняємо їх місцями.
т = НУМС[б-1];
НУМС[б-1] = НУМС[b];
НУМС[b] = т;
}
}
Чому в циклі for(а = 1; a<size; A ++) a<Сиз а не а =; b–) не можу розібрати.
І останнє
т = НУМС[б-1];
НУМС[б-1] = НУМС[b];
НУМС[b] = т;
Чи можна як-небудь спростити заміну?
Доброго дня.
Допоможіть, будь ласка, розібратися в методі. голову ламаю, не можу зрозуміти.
Є код з книжки:
#include
#include
using namespace std;
int main()
{
setlocale(LC_ALL, “російський”);
INT НУМС[10];
int a,b,T;
int size;
розмір = 10; // Кількість сортируемих елементів.
// Розміщуємо масив випадкові числа.
for(т = 0; T<size; т ++) НУМС[T] = rand()%100;
// Відображаємо вихідний масив.
cout << "Исходный массив:\n ";
for(т = 0; T<size; т ++) cout << НУМС[T] << ' ';
cout << '\n';
//Реалізація алгоритму бульбашкового сортування.
for(а = 1; а =; b–) {
if(НУМС[б-1] > НУМС[b]) { // Якщо значення елементів масиву
// розташовані не по порядку,
// то міняємо їх місцями.
т = НУМС[б-1];
НУМС[б-1] = НУМС[b];
НУМС[b] = т;
}
}
// Відображаємо відсортований масив.
cout << "\n Отсортированный массив:\n ";
for(т = 0; T<size; т ++) cout << НУМС[T] << ' ';
system("pause");
return 0;
}
Найбільше хвилює вкладені цикли:
for(а = 1; а =; b–)
У зовнішньому циклі чому a<size а не a = a що це таке і як воно працює?
І останнє:
Підкажіть, якомога вблагати перестановку:
т = НУМС[б-1];
НУМС[б-1] = НУМС[b];
НУМС[b] = т;
> Підкажіть, як можна спростити перестановку:
А що там спрощувати?
У C, C ++ і подібним їм мовами (паскаль, Java і ін.) обміняти значення 2-х змінних (і б) можна тільки чере 3-ю проміжну змінну (c):
c = a;
a = b;
b = c; // а и b поменялись значениями
У більш високорівневих мовах, таких як Python або Go, це можна було б записати простіше:
a, b = b, a
Можна спростити з помощю ф-циі swap() ;
своп(arrForSort[j],arrForSort[J-1]);
Можна записати через функцію swap() … тільки це навряд чи можна вважати спрощенням, тому що в цій функції робиться те ж саме.
але як мінімум не потрібно вводити 3 змінну
А в чому різниця ? … від однієї зайвої змінної…
Коли мова перейде від абсолютно елементарних завдань до більш-менш грунтовним, то один-два десятка змінних більше або менше – перестають грати якусь роль. Там вступають в гру інші критерії.
Про алгоритм бульбашкового сортування потрібно б ще запам'ятати те, що це найгірший (в сенсі ефективності, числа операцій) алгоритм сортування з усіх відомих.
Але здобувачі на співбесідах і студенти на іспитах упортно “tulyat” саме цей метод.
У цьому є якась загадка…
Так це звичка звичайна. Метод найпростіший для розуміння, ось і тулят його всюди.