Зараз ми розберемо на прикладах, як може виглядати алгоритм пошуку підрядка в рядку. Приклади будуть грунтуватися на функціях стандартних бібліотек, адже саме в таких функціях і проявляються всі зручності написання програм. А ось класичний розбір алгоритму, заснований на циклах і порівняннях, також досить примітний. Тому ми його розглянемо в цьому ж уроці.
Сам алгоритм в принципі дуже простий. Є два рядки. Наприклад "Привіт Світ" і "це"
Працювати будемо в два цикли:
- Перший буде виконувати прохід по всій рядку, і шукати місце розташування першої літери шуканої рядка ( "це" ).
- другий, починаючи з знайденої позиції першої літери – звіряти, які букви стоять після неї і скільки з них підряд збігаються.
Проілюструємо пошук підрядка в рядку:
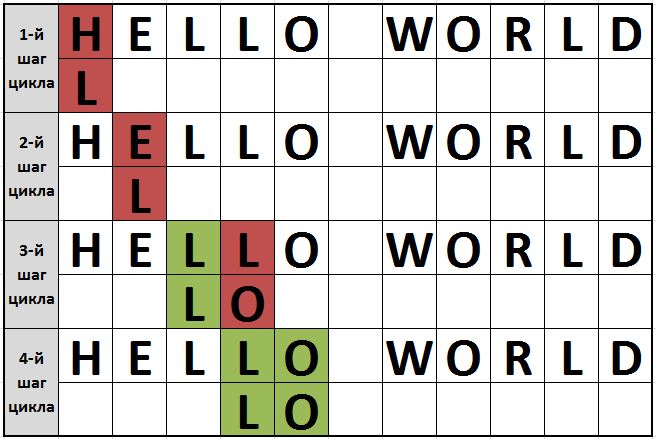
На перших двох ітераціях циклу порівнювані літери не будуть збігатися (виділено червоним). На третій ітерації шукана буква (перший символ шуканого слова) збіглася з символом у рядку, де відбувається пошук. При такому збігу в роботу включається другий цикл.
Він покликаний відраховувати кількість символів після першого в шуканої рядку, які будуть співпадати з символами в рядку вихідної. Якщо один з наступних символів не збігається – цикл завершує свою роботу. Немає сенсу ганяти цикл даремно, після першого розбіжності, так як вже зрозуміло, що шуканого тут немає.
На третій ітерації збігся тільки перший символ шуканої рядка, а ось другий вже не збігається. Доведеться першого циклу продовжити роботу. Четверта ітерація дає необхідні результати – збігаються всі символи шуканої рядка з частиною вихідної рядки. А раз все символи збіглися – подстрока знайдена. Роботу алгоритму можна закінчити.
Посмотрим, як виглядає класичний код пошуку підрядка в рядку в С ++:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #include <iostream> // Функция для поиска подстроки в строке // + поиск позиции, с которой начинается подстрока int pos(char *s, char *c, int n) { int i, j; // Счетчики для циклов int lenC, lenS; // Длины строк //Находим размеры строки исходника и искомого for (lenC = 0; c[lenC]; lenC++); for (lenS = 0; s[lenS]; lenS++); for (i = 0; i <= lenS - lenC; i++) // Пока есть возможность поиска { for (j = 0; s[i + j] == c[j]; j++); // Проверяем совпадение посимвольно // Если посимвольно совпадает по длине искомого // Вернем из функции номер ячейки, откуда начинается совпадение // Учитывать 0-терминатор ( '\0' ) if (j - lenC == 1 && i == lenS - lenC && !(n - 1)) return i; if (j == lenC) if (n - 1) n--; else return i; } //Иначе вернем -1 как результат отсутствия подстроки return -1; } int main() { char *s = "parapapa"; char *c = "pa"; int i, n = 0; for (i = 1; n != -1; i++) { n = pos(s, c, i); if (n >= 0) std:: cout << n << std:: endl; } } |
Два циклу виконують кожен свою задачу. Один тупотить по рядку в надії знайти “голову” шуканого слова (перший символ). другий з'ясовує, чи є після знайденої “голови” “тело” шуканого. причому перевіряє, чи не лежить це “тело” в кінці рядка. Тобто,. чи не є довжина знайденого слова на одиницю більше довжини шуканої рядка, якщо враховувати, що в цю одиницю потрапляє Нулла-термінатор ( ' 0' ).
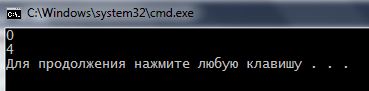
Ми бачимо, яка програма знайшла починають подстрокуПроте, в осередках символьного масиву з індексом 0 і 4. Але чому? Адже в словіParapapa 3 така послідовність. Вся справа в ' 0' .
В цілому зміст самого алгоритму на цьому закінчується. Більше ніяких складнощів крім нуля в кінці рядка немає. Однак, слід звернути увагу на множинність пошуку. що, якщо нам необхідно знайти в рядку кілька позицій?
Скільки разів шукане слово зустрічається в рядку і в яких місцях? Саме це і покликаний контролювати третій параметр – Int N – номер входження в рядок. Якщо поставити туди одиницю – він знайде перший збіг шуканого. якщо двійку, він змусить перший цикл пропустити чергу, будуть знайдені, і шукати другу. якщо трійку – шукати третє і так далі. З кожним знайденим шуканим словом, цей лічильник входжень зменшується на одиницю. Це і дозволяє описати пошук в циклі:
1 2 3 4 5 6 7 | for (i = 1; n != -1; i++) { n = pos(s, c, i); if (n >= 0) std:: cout << n << std:: endl; } |
Тобто знайти перше, друге, третій, четверте збіг… Поки функція не поверне -1, що вкаже на відсутність N-ного шуканого в рядку.
тепер, для порівняння, пошук підрядка в рядку С ++ з хедером string.
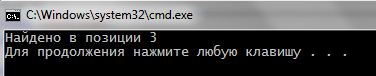
1 2 3 4 5 6 7 8 9 10 11 | #include <iostream> #include <string> using namespace std; int main() { setlocale(LC_ALL, "rus"); string s = "Hello world"; cout << "Найдено в позиции " << s.find("lo") << endl; } |
Все! клас string в С ++ забезпечений методом знайти(), повертає номер позиції, з якого починається тіло шуканої рядка в заданій стрічці. Результат:
Як же множинність? Так будь ласка:
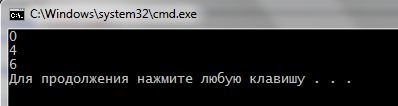
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include <iostream> #include <string> using namespace std; int main() { string s = "parapapa"; int i = 0; for ( i = s.find("pa", i++); i != string::npos; i = s.find("pa", i + 1)) cout << i << endl; } |
Функция знайти() приймає другим параметром номер символу, з якого почати пошук. Тобто,. знайшовши перше входження, його значення збільшується на одиницю і знайти() продовжує пошук з наступного символу після знайденої голови. Результат:
Все це є в С ++, і сам класс string досить зручний для роботи з рядками саме, як рядками, а не просто з масивом символів.
Мені сподобалося опис функції find(), пасиб
мені здається так краще, так як позбавляємося перевірки на нуль символ
Да, спасибо, дійсно так краще!
А в 22 рядку
if(п-1) що значить?
Взагалі то, в мові C, і успадковано в C ++, вважається, що числове значення 0 відповідає false (порушення умови), а будь-нульове значення – true (дотримання умови).
Тому формально if( n – 1 ) еквівалентними, якщо( n != 1 ).
P.S. формально тому, що в коректність коду взагалі я не вникав.
До такого запису слід звикнути, тому що в реальному коді на C / C ++ такий запис зустрічається досить часто, особливо при порівнянні указателей з значенням NULL:
int *ptr = ...
...
if( ptr ) { ... }
велике спасибі. надалі, буду знати
тоді в 20 рядку !(п-1) значить n = 1?