 Після того, как мы с вами познакомились со рядками і символьними масивами в C ++, розглянемо найпоширеніші функції для роботи з ними. Урок буде повністю побудований на практиці. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, як вони влаштовані. Стандартними опціями бібліотеки cstring относятся:
Після того, как мы с вами познакомились со рядками і символьними масивами в C ++, розглянемо найпоширеніші функції для роботи з ними. Урок буде повністю побудований на практиці. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, як вони влаштовані. Стандартними опціями бібліотеки cstring относятся:
- strlen() – подсчитывает длину строки (количество символов без учета \0);
- strcat() – объединяет строки;
- strcpy() – копіює символи одного рядка в іншу;
- strcmp() – порівнює між собою два рядки .
Это конечно не все функции, а только те, які ми розберемо в цій статті.
strlen() (от слова length – длина)
Наша программа, которая подсчитает количество символов в строке:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
Для подсчёта символов в строке неопределённой длины (так как вводит её пользователь), мы применили цикл while – строки 13 – 17. Он перебирает все ячейки массива (все символы строки) поочередно, начиная с нулевой. Коли на якомусь етапі циклу зустрінеться осередокourStr [amountOfSymbol], яка зберігає символ\0, цикл приостановит перебор символов и увеличение счётчика amountOfSymbol.
Так будет выглядеть код, з заміною нашої ділянки коду на функціюstrlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
Як бачите, этот код короче. В нем не пришлось объявлять дополнительные переменные и использовать цикл. В выходном потоке cout ми передали в функцію рядок – strlen(ourStr). Она посчитала длину этой строки и вернула в программу число. Как и в предыдущем коде-аналоге, символ \0 не включен в общее количество символов.
Результат буде і в першій програмі і в другій аналогічний:
 в C++")
strcat() (от слова concatenation – соединение)
Программа, яка в кінець одного рядка, дописывает вторую строку. Другими словами – объединяет две строки.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
За коментарями в коді повинно бути все зрозуміло. Нижче напишемо програму для виконання таких же дій, но с использованием strcat(). В цю функцію ми передамо два аргументи (две строки) – strcat(someText1, someText2); . Функція додасть рядокsomeText2 до рядкаsomeText1. При этом символ ' 0' в кінці someText1буде перезаписан першим символомsomeText2. Так само вона додасть завершальний ' 0'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Реализация объединения двух строк, используя стандартную функцию, заняла одну строчку кода в программе – 14-я строка.
Результат:

На що слід звернути увагу і першому і в другому коді– размер первого символьного массива должен быть достаточным для помещения символов второго массива. Если размер окажется недостаточным – может произойти аварийное завершение программы, так як запис рядка вийде за межі пам'яті, которую занимает первый массив. Наприклад:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
В этом случае, строковая константа“Учите С c нами!” не може бути записана в масивsomeText1. В нём недостаточно места, для такой операции.
Якщо ви використовуєте одну з останніх версій середовища розробки Microsoft Visual Studio, возможно возникновение следующей ошибки: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” Так происходит потому, що вже розроблена нова більш безпечна версія функціїstrcat – цеstrcat_s.
Она заботится о том, чтобы не произошло переполнение буфера (символьного массива, в который производится запись второй строки). Среда предлагает вам использовать новую функцию, вместо устаревшей. Почитать больше об этом можно на сайте msdn. Подобная ошибка может появиться, якщо ви будете застосовувати функціюstrcpy, о которой речь пойдет ниже.
strcpy() (от слова copy – копирование)
Реализуем копирование одной строки и её вставку на место другой строки.
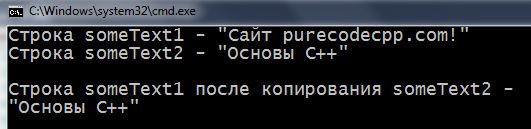
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Застосуємо стандартну функцію бібліотекиcstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Пробуйте компилировать и первую, и вторую программу. Увидите такой результат:
strcmp() (от слова compare – сравнение)
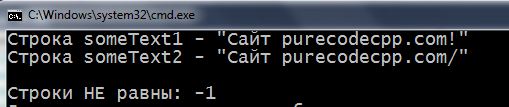
Эта функция устроена так: она сравнивает две Си-строки символ за символом. Если строки идентичны (и по символам и по их количеству) – функция возвращает в программу число 0. Якщо перший рядок довший другий – повертає в програму число 1, а если меньше, те -1. Число -1 повертається і тоді, когда длина строк равна, но символы строк не совпадают.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
 програма зstrcmp():
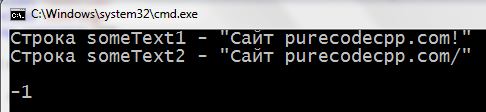
програма зstrcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Діліться в соціальних мережах нашими статтями зі своїми знайомими, которые так же изучают основы программирования на языке С .
while (true) // запускаем бесконечный цикл
{
someText1[count] = someText2[count]; // копіюємо посимвольний
if (someText2[count] == « 0») // если нашли \0 у второй строки
{
break; // прерываем цикл
}
count ;
}
Мені не зрозуміло куди поділася решта рядка “Сaйт purecodecpp.com!” ,
якщо по ідеї повинно вийти так: Основи С ++ pp.com.
Ми копіюємо посимвольний меншу рядок у велику, так чому залишок someText1 видаляється?
тому, що ми копіюємо не меншу у велику, а другу в першу. І коли підійде ' 0’ у другому рядку він теж перезапише в перший масив. Далі, коли буде зчитуватися перший масив, то цей нуль і покаже кінець рядка і не важливо, що там було за ним записано. Це буде кінець рядка.
як визначити найдовше слова в рядку і його довжину?
#include
#include
using namespace std;
int main()
{
setlocale(LC_ALL, “rus”);
голець string_Array_1[] = “Вася, ти що, втомився?”;
голець string_Array_2[] = “Вася, ти що, втомився!”;
cout << "Первая строка – \"" << string_Array_1 << "\"\n";
cout << "Вторая строка – \"" << string_Array_2 << "\"\n";
cout << "=====================================================\n\n";
cout << "Если строки идентичны и по символам и по количеству, те: 0\n";
cout << "Если первая строка длиннее второй, те: +1\n";
cout << "Если первая строка короче второй, те: -1\n";
cout << "Если длина строк равна, але символи не збігаються, те: -1\n";
cout << "=====================================================\n\n";
cout << "В приведенном случае получился ответ: " << strcmp(string_Array_1 , string_Array_2);
cout << endl << endl;
return 0;
}
вийдуть:
перший рядок – "Вася, ти що, втомився?"
Другий рядок – "Вася, ти що, втомився!"
================================================== ========
Якщо рядки ідентичні і за символами і за кількістю, те: 0
Якщо перший рядок довший другий, те: +1
Якщо перший рядок коротше другий, те: -1
Якщо довжина рядків дорівнює, але символи не збігаються, те: -1
================================================== =========
У наведеному випадку вийшов відповідь: 1
Не можу зрозуміти, чому 1, якщо в кінцях рядків різні символи: ? і !
Цікавий баг в цьому коді.
скопіював, зробив два однакових тексту “Вася, ти що, втомився!” в символ string_Array_1[] і символ string_Array_2[] і перевірив:
1. Поки рядки однакові то все GOOD!!!
2. Якщо перший рядок зробити довше то отримую ” -1 ” (інвертовану).
3. Якщо перший рядок зробити коротше то отримую ” 1 ” (інвертовану).
далі цікавіше.
4. Якщо в першому рядку в слові ” втомився ” букву ” у ” поміняти на ” т ” то отримую ” -1 ”
5. Якщо в першому рядку в слові ” втомився ” букву ” у ” поміняти на ” е ” то отримую ” 1 ”
6. Якщо у другому рядку в слові ” втомився ” букву ” у ” поміняти на ” т ” то отримую ” 1 ”
7. Якщо у другому рядку в слові ” втомився ” букву ” у ” поміняти на ” т ” то отримую ” -1 ”
слово ” втомився ” я взяв для прикладу. букву ” у ” я міняв на попередню і наступну в алфавіті. Це працює з будь-заміною букв ( ” а ” і ” я ” я не зміг поміняти).
Це не баг (як я думав). Це пов'язано з кодуванням ASCII. Саму кодування ASCII можна загугли. Ось і виходить що “у” по цьому кодуванні більше “т” і менше “е”
Получается, що '?’ довше ніж '!’
Это так???
Чим більше код символу в таблиці ASCII тим “довше”.
“B” довше “А”, а “D” довше “B”.
Знаків пунктуації це теж стосується.
У “!” код 33, в “?” код 63, значить ? > !
Да, трохи розібравшись я зрозумів (здогадався) що тут йде прив'язка до кодуванні ASCII
Припускаю що функція просто складає все числа і порівнює суму 1 рядки з сумою 2.
замінив рядки
“АааааАаааааааааааааааааааааааа”
“ZzzzzZzzzzZzzzzZzzzzZzzzzZzzz”
відповідь була -1
незважаючи на те що 1 рядок довший. Ну я маю право помилятися :))
>>Да, трохи розібравшись я зрозумів (здогадався) що тут йде прив'язка до >>кодуванні ASCII
ніякий “прив'язки” до кодування немає, порівнюються числа, для процесора не існує ні кодувань ні символів, а є тільки числа і то в двійковій системі числення!
Доброго дня. Маю питання є запитання. Як можна записати введений з консолі текст в масив, не оголошуючи його заздалегідь. К примеру, якщо ми не знає розмір рядка, яку введе користувач, але і не хочемо заздалегідь оголошувати порожній масив
з випадковим розміром (раптом ми вкажемо менший розмір, ніж той який потрібен.).Виходить що користувач вводить рядок, натискає введення і далі, повинен створитися масив відповідний для зберігання цього набору символів.
Для цього потрібно створити динамічний масив
Можете допомогти? Як записати текст у матрицю рядками і потім переписати її від центру по спіралі?