 Після того, как мы с вами познакомились со рядками і символьними масивами в C ++, розглянемо найпоширеніші функції для роботи з ними. Урок буде повністю побудований на практиці. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, як вони влаштовані. Стандартними опціями бібліотеки cstring относятся:
Після того, как мы с вами познакомились со рядками і символьними масивами в C ++, розглянемо найпоширеніші функції для роботи з ними. Урок буде повністю побудований на практиці. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, як вони влаштовані. Стандартними опціями бібліотеки cstring относятся:
- strlen() – подсчитывает длину строки (количество символов без учета \0);
- strcat() – объединяет строки;
- strcpy() – копіює символи одного рядка в іншу;
- strcmp() – порівнює між собою два рядки .
Это конечно не все функции, а только те, які ми розберемо в цій статті.
strlen() (от слова length – длина)
Наша программа, которая подсчитает количество символов в строке:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
Для подсчёта символов в строке неопределённой длины (так как вводит её пользователь), мы применили цикл while – строки 13 – 17. Он перебирает все ячейки массива (все символы строки) поочередно, начиная с нулевой. Коли на якомусь етапі циклу зустрінеться осередокourStr [amountOfSymbol], яка зберігає символ\0, цикл приостановит перебор символов и увеличение счётчика amountOfSymbol.
Так будет выглядеть код, з заміною нашої ділянки коду на функціюstrlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
Як бачите, этот код короче. В нем не пришлось объявлять дополнительные переменные и использовать цикл. В выходном потоке cout ми передали в функцію рядок – strlen(ourStr). Она посчитала длину этой строки и вернула в программу число. Как и в предыдущем коде-аналоге, символ \0 не включен в общее количество символов.
Результат буде і в першій програмі і в другій аналогічний:
 в C++")
strcat() (от слова concatenation – соединение)
Программа, яка в кінець одного рядка, дописывает вторую строку. Другими словами – объединяет две строки.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
За коментарями в коді повинно бути все зрозуміло. Нижче напишемо програму для виконання таких же дій, но с использованием strcat(). В цю функцію ми передамо два аргументи (две строки) – strcat(someText1, someText2); . Функція додасть рядокsomeText2 до рядкаsomeText1. При этом символ ' 0' в кінці someText1буде перезаписан першим символомsomeText2. Так само вона додасть завершальний ' 0'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Реализация объединения двух строк, используя стандартную функцию, заняла одну строчку кода в программе – 14-я строка.
Результат:

На що слід звернути увагу і першому і в другому коді– размер первого символьного массива должен быть достаточным для помещения символов второго массива. Если размер окажется недостаточным – может произойти аварийное завершение программы, так як запис рядка вийде за межі пам'яті, которую занимает первый массив. Наприклад:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
В этом случае, строковая константа“Учите С c нами!” не може бути записана в масивsomeText1. В нём недостаточно места, для такой операции.
Якщо ви використовуєте одну з останніх версій середовища розробки Microsoft Visual Studio, возможно возникновение следующей ошибки: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” Так происходит потому, що вже розроблена нова більш безпечна версія функціїstrcat – цеstrcat_s.
Она заботится о том, чтобы не произошло переполнение буфера (символьного массива, в который производится запись второй строки). Среда предлагает вам использовать новую функцию, вместо устаревшей. Почитать больше об этом можно на сайте msdn. Подобная ошибка может появиться, якщо ви будете застосовувати функціюstrcpy, о которой речь пойдет ниже.
strcpy() (от слова copy – копирование)
Реализуем копирование одной строки и её вставку на место другой строки.
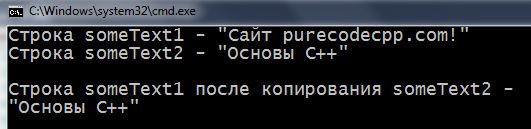
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Застосуємо стандартну функцію бібліотекиcstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Пробуйте компилировать и первую, и вторую программу. Увидите такой результат:
strcmp() (от слова compare – сравнение)
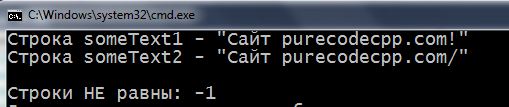
Эта функция устроена так: она сравнивает две Си-строки символ за символом. Если строки идентичны (и по символам и по их количеству) – функция возвращает в программу число 0. Якщо перший рядок довший другий – повертає в програму число 1, а если меньше, те -1. Число -1 повертається і тоді, когда длина строк равна, но символы строк не совпадают.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
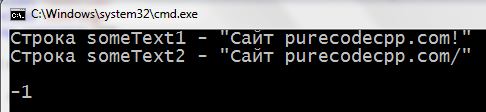
 програма зstrcmp():
програма зstrcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Діліться в соціальних мережах нашими статтями зі своїми знайомими, которые так же изучают основы программирования на языке С .
Вітаю. Скажіть будь ласка, чому коли об'єднуємо два рядки і другого символьному масиву задаємо довжину масиву, например
, то в цьому випадку другий масив що не об'єднується з першим?
Це не правда.
У вас результат може просто не поміщатися в someText1[].
Збільште його розмір – чого скупитися?
Наприклад: someText1[ 200 ]
Поясніть, будь ласка, чому в прикладі з об'єднанням рядків
int count1 = 0; // для індексу осередку де зберігається ' 0’ першого рядка
while (someText1[count1] != 0)
ми пишемо “someText1[count1] != 0” а не “someText1[count1] != ‘\0′”?
Ми ж начебто шукаємо елемент закінчення символьного рядка ' 0'? При чому тут нуль?
Хоча мушу зауважити, у мене а Коудблоксе працює і з нулем…
Тому що запис ' 0’ як-раз і означає: байт, чисельне значення записане в який так само 0.
Такі записи еквівалентні.
Шановний автор!
По-моєму, в першому прикладі порівнянь рядків пропущена директива препроцесору #include
Подружжя не можу зрозуміти
голець xsmibol[2] = {WPARAM, « 0»};
ось так працює
————————–
А ось так не працює:
голець xsmibol[2];
xsmibol = {WPARAM, « 0»};
каже 17 27 C:\Users 1 Documents main1.cpp [УВАГА] розширені списки ініціалізатор доступні тільки з -std = C ++ 11 або -std = гну ++ 11
17 12 C:\Users 1 Documents main1.cpp [помилка] призначаючи на масив зі списку ініціалізаторів
37 14 C:\Users 1 Documents main1.cpp [помилка] очікується, первинне вираження, перш ніж «)’ знак
Що я роблю не так ?
Я вважаю, що в першому випадку – голець xsmibol[2] = {WPARAM, « 0»}; компілятор сам обчислює розмір рядка і підставляє за місце 2. А в другому випадку -char xsmibol[2];
xsmibol = {WPARAM, « 0»}; він вже не може виправити розмір рядка.
Тому що масиву допускається ініціалізація списком значень ({…,…}), але не дозволено привласнення. Це синтаксичні правила C ++, і це не залежить від типу елементів масиву – будь це масив char (строки), або масив int, масив float і т.д.
P.S. Це обмеження частково знижено в стандарті C ++ 11 (2011м), але його потрібно вказувати опціями компіляції.
Доброго дня. Вчуся по вашим урокам і вирішую задачі.
Однак зауважив деяка розбіжність в результатах по функції strcmp.
У разі збігу кількості символів в двох рядках , але відмінності цих символів результат 1 или -1 залежить від того в якій послідовності ці символи. Якщо перший рядок містить символи , які за алфавітом ваше ніж у другому рядку то результат 1, якщо навпаки то результат -1. Наприклад: порівняння рядків “ASDF” і “bsdf”видасть 1, а порівняння рядків “bsdf” і “ASDF” видасть -1. Теж і з числами. “1234” і “2234” видасть 1, а “2234” і “1234” видасть -1.
перепрошую, навпаки "1234" і "2234" видасть -1, а "2234" і "+1234" видасть 1.
цілком природно – операція порівняння не комутативна, вона не допускає перестановку операндов. Те ж саме і для числових значень і їх порівняння (це зрозуміліше): 2 > 1 – це true, але 1 > 2 – це false.
Вітаю!
Скажіть, будь ласка, чому, в прикладі з об'єднанням двох рядків за допомогою циклів, ми обов'язково вказуємо розмірність першого строкового масиву?:
char someText1[64] = “Сайт purecodecpp.com!”;
char someText2[] = “Учите С c нами!”;
А якщо залишити розмірність незаповненою, дозволивши компілятору самостійно підрахувати це значення, то після компіляції в консолі виводиться об'єднаний текст, плюс якийсь випадковий символ(абсолютно рандомний), після чого з'являється вікно з помилкою:
(например, в даному випадку, додався знак питання:
someText1: Сайт purecodecpp.com!Учите С c нами!?
замість – someText1: Сайт purecodecpp.com!Учите С c нами!
Тому що вказуючи someText1[64] вы rezerviruete за рядком 64 байт памяти, хоча сама записана туди рядок "Сайт purecodecpp.com!», обмежена ' 0', займає набагато менше байт (strlen(someText1)).
А коли ви записуєте someText1[], компілятор вираховує і резервує для цієї рядки не 64 байт, а рівно стільки, скільки потрібно для розміщення зазначеного рядка + кінцевий символ ' 0'.
Як тільки ви намагаєтеся виконати дописування someText2 в хвіст someText1, в 1-му випадку копіювання відбувається ось в ті 64 зарезервованих байтів. А в 2-м випадку ви відразу починаєте писати межа виділеної для someText1 пам'яті, і результату буде непередбачуваний – це груба ошибка.
Вітаю, переписала в програму ваш перший код, запустила – пробую… Пишу для перевірки одне слово, щоб перевірити чи коректно видасть відповідь, і так, слово: “літо”, складається з 4-х символів, в написанні не використовувалися не пробілів, НЕ лапки, тільки лист… а програми видає:
“Строка “літо” состоит из 8 символов!”
…8-мені? Почему? :) Хіба не 4 символи? Аналогічно і з двома словами:
“літо ранок”
“Строка “літо ранок” состоит из 17 символов!”
кожна буква, вважається компілятором як 2 символи, пробіл – 1 символ. Але ж кожен символ має вважатися як 1… ?
Так і не зрозумів як нормально писати великий текст таким способом – ‘Ж’, і так далі – навіть одну букву довго писати…. щоб не просто лапки!? може я не зрозумів щось!?