Сейчас мы разберём на примерах, как может выглядеть алгоритм поиска подстроки в строке. Примеры будут основываться на функциях стандартных библиотек, ведь именно в таких функциях и проявляются все удобства написания программ. А вот классический разбор алгоритма, основанный на циклах и сравнениях, также достаточно примечателен. Поэтому мы его рассмотрим в этом же уроке.
Сам алгоритм в принципе очень прост. Есть две строки. Например "Hello world" и "lo"
Работать будем в два цикла:
- Первый будет выполнять проход по всей строке, и искать местоположение первой буквы искомой строки ( "lo" ).
- Второй, начиная с найденной позиции первой буквы – сверять, какие буквы стоят после неё и сколько из них подряд совпадают.
Проиллюстрируем поиск подстроки в строке:
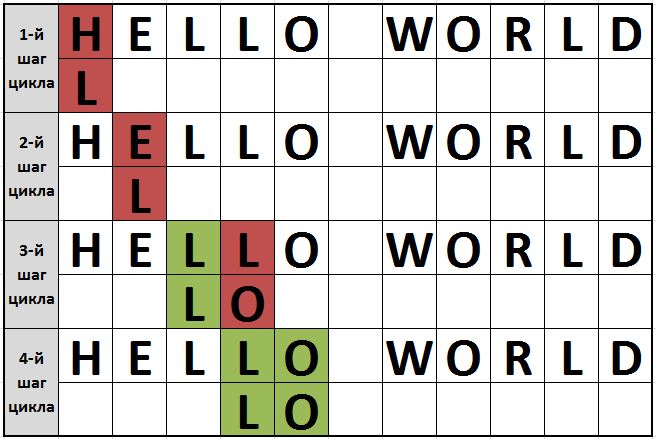
На первых двух итерациях цикла сравниваемые буквы не будут совпадать (выделено красным). На третьей итерации искомая буква (первый символ искомого слова) совпала с символом в строке, где происходит поиск. При таком совпадении в работу включается второй цикл.
Он призван отсчитывать количество символов после первого в искомой строке, которые будут совпадать с символами в строке исходной. Если один из следующих символов не совпадает – цикл завершает свою работу. Нет смысла гонять цикл впустую, после первого несовпадения, так как уже понятно, что искомого тут нет.
На третьей итерации совпал только первый символ искомой строки, а вот второй уже не совпадает. Придется первому циклу продолжить работу. Четвертая итерация дает необходимые результаты – совпадают все символы искомой строки с частью исходной строки. А раз все символы совпали – подстрока найдена. Работу алгоритма можно закончить.
Посмотрим, как выглядит классический код поиска подстроки в строке в С++:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | #include <iostream> // Функция для поиска подстроки в строке // + поиск позиции, с которой начинается подстрока int pos(char *s, char *c, int n) { int i, j; // Счетчики для циклов int lenC, lenS; // Длины строк //Находим размеры строки исходника и искомого for (lenC = 0; c[lenC]; lenC++); for (lenS = 0; s[lenS]; lenS++); for (i = 0; i <= lenS - lenC; i++) // Пока есть возможность поиска { for (j = 0; s[i + j] == c[j]; j++); // Проверяем совпадение посимвольно // Если посимвольно совпадает по длине искомого // Вернем из функции номер ячейки, откуда начинается совпадение // Учитывать 0-терминатор ( '\0' ) if (j - lenC == 1 && i == lenS - lenC && !(n - 1)) return i; if (j == lenC) if (n - 1) n--; else return i; } //Иначе вернем -1 как результат отсутствия подстроки return -1; } int main() { char *s = "parapapa"; char *c = "pa"; int i, n = 0; for (i = 1; n != -1; i++) { n = pos(s, c, i); if (n >= 0) std:: cout << n << std:: endl; } } |
Два цикла выполняют каждый свою задачу. Один топает по строке в надежде найти “голову” искомого слова (первый символ). Второй выясняет, есть ли после найденной “головы” “тело” искомого. Причем проверяет, не лежит ли это “тело” в конце строки. Т.е. не является ли длина найденного слова на единицу больше длины искомой строки, если учитывать, что в эту единицу попадает нулль-терминатор ( '\0' ).
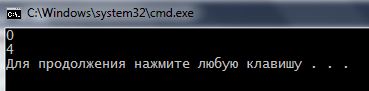
Мы видим, что программа нашла начало подстроки pa в ячейках символьного массива с индексом 0 и 4. Но почему? Ведь в слове parapapa 3 таких подстроки. Все дело в '\0' .
В целом смысл самого алгоритма на этом заканчивается. Больше никаких сложностей кроме нуля в конце строки нет. Однако, следует обратить внимание на множественность поиска. Что, если нам необходимо найти в строке несколько позиций?
Сколько раз искомое слово встречается в строке и в каких местах? Именно это и призван контролировать третий параметр – int n – номер вхождения в строку. Если поставить туда единицу – он найдет первое совпадение искомого. Если двойку, он заставит первый цикл пропустить найденное первое, и искать второе. Если тройку – искать третье и так далее. С каждым найденным искомым словом, этот счетчик вхождений уменьшается на единицу. Это и позволяет описать поиск в цикле:
1 2 3 4 5 6 7 | for (i = 1; n != -1; i++) { n = pos(s, c, i); if (n >= 0) std:: cout << n << std:: endl; } |
То есть найти первое, второе, третье, четвертое совпадение… Пока функция не вернет -1, что укажет на отсутствие N-ного искомого в строке.
Теперь, для сравнения, поиск подстроки в строке С++ с хедером string.
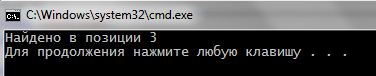
1 2 3 4 5 6 7 8 9 10 11 | #include <iostream> #include <string> using namespace std; int main() { setlocale(LC_ALL, "rus"); string s = "Hello world"; cout << "Найдено в позиции " << s.find("lo") << endl; } |
Все! Класс string в С++ снабжен методом find(), возвращающий номер ячейки, с которого начинается тело искомой строки в исходной строке. Результат:
Как же множественность? Да пожалуйста:
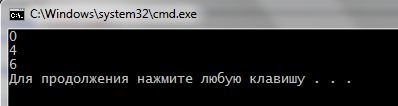
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include <iostream> #include <string> using namespace std; int main() { string s = "parapapa"; int i = 0; for ( i = s.find("pa", i++); i != string::npos; i = s.find("pa", i + 1)) cout << i << endl; } |
Функция find() принимает вторым параметром номер символа, с которого начать поиск. Т.е. найдя первое вхождение, его значение увеличивается на единицу и find() продолжает поиск со следующего символа после найденной головы. Результат:
Всё это есть в С++, и сам класс string достаточно удобный для работы со строками именно, как строками, а не просто с массивом символов.
Мне понравилось описание функции find(), пасиб
мне кажется так лучше, так как избавляемся проверки на ноль символ
Да, спасибо, действительно так лучше!
А в 22 строке
if(n-1) что значит?
Вообще то, в языке C, и унаследовано в C++, считается, что числовое значение 0 соответствует false (нарушению условия), а любое ненулевое значение – true (соблюдению условия).
Поэтому формально if( n – 1 ) равнозначно if( n != 1 ).
P.S. Формально потому, что в корректность кода вообще я не вникал.
К такой записи следует привыкнуть, потому что в реальном коде на C/C++ такая запись встречается достаточно часто, особенно при сравнении указателей с значением NULL:
int *ptr = ...
...
if( ptr ) { ... }
Спасибо большое. Впредь, буду знать
Тогда в 20 строке !(n-1) значит n=1?
А ПОЧЕМУ ОПИСАНИЕ STRING В КОНЦЕ? 2 дня разбирал перебор через char*)
Александр, здравствуйте! Спасибо за ваш комментарий, он приблизил сообщество программистов к тому, чтобы соблюдать все тонкости и нюансы грамотного и понятного построения программного кода на прекрасном языке C/C++, который исключает тот факт, что человек, так глубоко интересующегося информационными технологиями, будет иметь несчастье запутаться и 2 дня разбирать перебор через char*. Искренне благодарим вас и желаем исключительно понятного кода на просторах глобальной сети.