, strcat (), strcpy (), strcmp ()") После того, как мы с вами познакомились со строками и символьными массивами в C++, рассмотрим самые распространённые функции для работы с ними. Урок будет полностью построен на практике. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, как они устроены. К стандартным функциям библиотеки cstring относятся:
После того, как мы с вами познакомились со строками и символьными массивами в C++, рассмотрим самые распространённые функции для работы с ними. Урок будет полностью построен на практике. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, как они устроены. К стандартным функциям библиотеки cstring относятся:
- strlen() – подсчитывает длину строки (количество символов без учета \0);
- strcat() – объединяет строки;
- strcpy() – копирует символы одной строки в другую;
- strcmp() – сравнивает между собой две строки .
Это конечно не все функции, а только те, которые мы разберём в этой статье.
strlen() (от слова length – длина)
Наша программа, которая подсчитает количество символов в строке:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
Для подсчёта символов в строке неопределённой длины (так как вводит её пользователь), мы применили цикл while – строки 13 – 17. Он перебирает все ячейки массива (все символы строки) поочередно, начиная с нулевой. Когда на каком-то шаге цикла встретится ячейка ourStr [amountOfSymbol], которая хранит символ \0, цикл приостановит перебор символов и увеличение счётчика amountOfSymbol.
Так будет выглядеть код, с заменой нашего участка кода на функцию strlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
Как видите, этот код короче. В нем не пришлось объявлять дополнительные переменные и использовать цикл. В выходном потоке cout мы передали в функцию строку – strlen(ourStr). Она посчитала длину этой строки и вернула в программу число. Как и в предыдущем коде-аналоге, символ \0 не включен в общее количество символов.
Результат будет и в первой программе и во второй аналогичен:
 в C++")
strcat() (от слова concatenation – соединение)
Программа, которая в конец одной строки, дописывает вторую строку. Другими словами – объединяет две строки.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
По комментариям в коде должно быть всё понятно. Ниже напишем программу для выполнения таких же действий, но с использованием strcat(). В эту функцию мы передадим два аргумента (две строки) – strcat(someText1, someText2); . Функция добавит строку someText2 к строке someText1. При этом символ '\0' в конце someText1 будет перезаписан первым символом someText2. Так же она добавит завершающий '\0'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Реализация объединения двух строк, используя стандартную функцию, заняла одну строчку кода в программе – 14-я строка.
Результат:

На что следует обратить внимание и первом и во втором коде – размер первого символьного массива должен быть достаточным для помещения символов второго массива. Если размер окажется недостаточным – может произойти аварийное завершение программы, так как запись строки выйдет за пределы памяти, которую занимает первый массив. Например:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
В этом случае, строковая константа “Учите С++ c нами!” не может быть записана в массив someText1. В нём недостаточно места, для такой операции.
Если вы используете одну из последних версий среды разработки Microsoft Visual Studio, возможно возникновение следующей ошибки: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” Так происходит потому, что уже разработана новая более безопасная версия функции strcat – это strcat_s.
Она заботится о том, чтобы не произошло переполнение буфера (символьного массива, в который производится запись второй строки). Среда предлагает вам использовать новую функцию, вместо устаревшей. Почитать больше об этом можно на сайте msdn. Подобная ошибка может появиться, если вы будете применять функцию strcpy, о которой речь пойдет ниже.
strcpy() (от слова copy – копирование)
Реализуем копирование одной строки и её вставку на место другой строки.
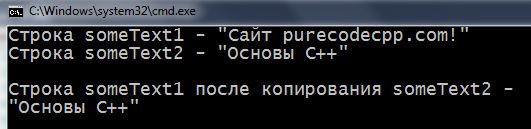
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Применим стандартную функцию библиотеки cstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Пробуйте компилировать и первую, и вторую программу. Увидите такой результат:
strcmp() (от слова compare – сравнение)
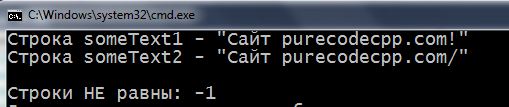
Эта функция устроена так: она сравнивает две Си-строки символ за символом. Если строки идентичны (и по символам и по их количеству) – функция возвращает в программу число 0. Если первая строка длиннее второй – возвращает в программу число 1, а если меньше, то -1. Число -1 возвращается и тогда, когда длина строк равна, но символы строк не совпадают.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
 Программа с strcmp():
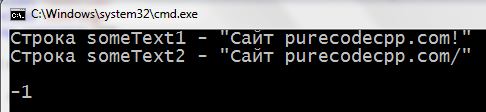
Программа с strcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Делитесь в социальных сетях нашими статьями со своими знакомыми, которые так же изучают основы программирования на языке С++.
Есть мильярд штук, которые вы пропустили, но очень подробно описали очевидное…
>> Программа, которая в конец одной строки, дописывает вторую строку. Другими словами – объединяет две строки.
И так, и другими словами – всяко разно, а суть не ясна.
у меня 2 строки char* под каждую выделено 256 байт.
В первую записано “hello”, во вторую “world”.
Я их объединяю. Сколько байт мне надо? 512 или 10?
Отвечаете и идем дальше по тексту :).
Владимир, тема указателей в этой статье не поднималась. Если говорить о символьных массивах (Си-строках) размером в 256 байт каждый, то после объединения строк “hello” и ” world”, строка в которую дописали символы world, будет занимать 256 байт, как и до объединения.
#include#include
using namespace std;
int main()
{
setlocale(LC_ALL, "rus");
char strHello[256] = "hello"; // все ячейки после hello будут содержать символ /0
char strWorld[256] = " world";
strcat(strHello, strWorld);
cout < < strHello << endl << endl; cout << "Размер строки strHello в байтах после объединения = " << sizeof(strHello) << endl; // функция sizeof() возвращает размер в байтах, переданного ей аргумента return 0; }
Строка strWorld займет ячейки строки strHello, следующие за символами hello (первый символ строки strWorld "затрет" \0 после символа 'o' строки strHello).
Работая с указателями на строки, конечно, лучше перевыделять необходимое количество памяти для хранения символов строк и не занимать лишнее место. Получится, что необходимо 12 байт для "hello world". Все по порядку - дойдем и до этого :)
P.S. комментарии,код и разъяснения не для тебя, а для новичков, которые будут читать то о чем мы говорим
Могу я написать
strcat(strHello, strHello)
?
Почему?
Вопрос действительно очень интересный! Мне раньше не приходилось задуматься над этим. На первый взгляд, в этой записи нет ничего странного. Но ведь не работает же! :) Ошибка гласит “Буфер слишком мал”. Один мой знакомый (Виталий) ответил мне так на этот вопрос: “в документации написано, что “если объекты функции перекрываются, её поведение не определяется.” программиста который так напишет засосет в void )) ” Ну и ещё так продолжил: “копирование идет посимвольно. Функция ищет \0 в первой строке, находит, и начинает туда посимвольно клеить вторую строку. НО! она будет клеить пока не найдет \0 которого УЖЕ НЕТ!
Вова, будем благодарны, если ты тоже ответишь нам на этот вопрос.
память то уже выделена
Ну правильно товарищ сказал, первая строка копирует символы из своего начала в свой конец, поэтому растет бесконечно.
В мане написано:
Строки не могут перекрываться, а в dest должно быть достаточно места для размещения результата.
Реально происходит переполнение буфера, но чисто случайно это может сработать (ошибка не вылезет), но программа модифицируется как-нибудь непредсказуемо.
Докапался то я к тому, что описание этой функции в мане занимает строчек 6. Просто, понятно и все сразу (и про буферы достаточного размера и про пересечение строк). Вы пишите сто раз одно и тоже разными словами, не знаю зачем xD.
>> P.S. комментарии,код и разъяснения не для тебя, а для новичков, которые будут читать то о чем мы говорим.
Ты ведь писала статью про соглашения о кодировании. Вроде как в некоторых из них указывается оптимальное количество комментариев в коде. К каждой строке никто не пишет.
Вроде как код не индексируется поисковиком (или я ошибаюсь?), поэтому просто выгоднее описание к коду помещать после кода, а не внутри.
Ты пишешь, “функции для работы со строками в С++”, реально они когда-то лежали в , но в С++ есть , а старые (“сишные”) строки вынесены в (вот там и описаны эти всякие strcat, … ). Т.е. я прочитал заголовок и ожидал прочитать про std::string, а тут… (меня обманули xD).
так в коде нет комментариев в каждой строке )) там всего их пара штук. P.S. написан был для того, чтобы ты не подумал будто я тебе все это объясняю. Ты то знаешь – это понятно ))
По поводу заголовка. К названию конечно можно придираться… Только если бы статья была о string, ее тоже не назовешь “функции для работы со строками в С++”. Скорее – Методы для работы со строками объектами класса string.
Как бы ты назвал данную статью? Может и правда лучше переименовать.
Но читаю статью дальше…
Про strcpy ты привела что-то типа аналога, т.е. попыталась запилить strcpy своими руками, я верно понимаю?
точно
Не точно xD.
В мане (в стандарте видимо тоже) написано что строки не могут перекрываться. В gcc вроде бы перекрывающиеся строки отрабатывают нормально, но по стандарту это может быть неопределенное поведение, а значит в другом компилятор (другой версии этого же компилятора) оно может сломаться.
Я думаю, что по этой теме лучше описать типичные ошибки (с strcpy – это переполнение буффера) и способы борьбы.
Я бы про поделки мелкософта вспомнил, типа strcpy_s. Если вы пишите код в вижуал студии, то стопудово вам в окно сыпятся предупреждения о том, что strcpy надо заменить на безопасную версию – strcpy_s. Вот про эту штуку можно написать ИМХО.
Посмотрите тут
ну о strcpy_s и о strcat_s – это мой был к тебе вопрос )) Получается теперь, что вопрос сама себе задала.
Интересная у тебя манера общения:
– Точно.
– Не точно.
+ Мои вопросы мне же и задаешь…
Вова. Предлагаю общаться так, будто мы очень уважаем друг-друга )
но вцелом статьи стали годнее, код отформатирован хотя бы единообразно :). Более веселых примеров не хватает, что-ли…
Пишите еще :)
ну знаешь, ты не на КВН заглянул :)
>> Вова. Предлагаю общаться так, будто мы очень уважаем друг-друга )
“На Вы” что-ли? )
Про более правильные названия статей ничего не знаю. Я не любитель микростатей, я бы написал под таким названием и про Си-строки, и про string. Придумал бы какой-нибудь пример, в который свел бы кучу строковых функций, а к самим функциям написал бы очень короткие (отнострочные) комментарии, свел бы их в таблицу. Написал бы про переполнения буферов – это вобще типичная ошибка при работе со строками, safe-функции от микрософта и еще пример типа… “дан массив строк, надо слить его в одну большую строку” – тут бы остановился на оценке асимптотической сложности – пример шикарен и оценка сложности не лежит на поверхности.
Я не столько вопросы задаю, сколько предлагаю темы для следующих статей (или тезисы к допилу текущей).
В любом случае – спасибо за конструктивную критику и предложения! Интересно с тобой общаться
Про пример со слиянием массива строк поясню.
у strcat есть артефакт, ты вот верно уже написала, что перед тем как приступить к слиянию, он заменяет символ . Но чтобы его занменить, его надо найти. А как его найти, если размер строки не известен? – перебрать последовательно все элементы строки.
Если ты сливаешь 2 строки – первая длиной N, вторая – M, то будет выполнено N + M операций, т.к. сначала N операций для поиска , а затем M операций для записи содержимого второй строки в первую.
Хотя, многие программисты, не заглянув в документацию ожидают M операций, т.к. про поиск забывают.
Соответственно, если у нас есть массив из K строк и выйдет так, что первая строка очень длинная, а остальные очень короткие, то сложность алгоритма будет не очень маленькой (хотя, мы ведь добавляет короткие строки к длинной), а близкой к K * Len, где Len – сумма длинн всех строк. Короче квадратичная сложность вместо линейной.
А вот в std::string все совсем иначе, хотя сложность останется такой же (примерно, ведь есть штуки типа memcpy и вектор может расти рывками) несмотря на то, что размер строк известен. Думайте почему, МБ статью новую нарисуете.
Пару строк в защиту Автора!
Владимир, обращаюсь к Вам “Про более правильные названия статей ничего не знаю” – нечего придираться к придуманному названию, а то выходит – мне не нравится, но не знаю как лучше… “я бы написал…”, “придумал бы…”, ” свел бы…” и т. д. и т.п. Но не написал, не придумал, не свел… (если я слишком категоричен или глубоко не прав – поделитесь, будьте любезны ссылкой на Вашу статью на аналогичную тему). А кто-то написал, придумал, сделал. А Вы теперь сидиете “весь такой умный” и критикуете. Я бы тоже много чего хорошего сделал…. В то время как кто-то берет и делает! Мне например и статьи очень нравятся и примеры понятные. Изложение куда понятнее чем у моего нынешнего преподавателя по С++ в ВУЗе (еще один комплимент автору). Много тем освоил благодаря этому сайту а не занятиям и конспектам (как не печально). Автор, спасибо за Ваш труд! Не останавливайтесь на достигнутом, Ваши старания приносят пользу людям!
первый пример про сравнение 2х строк у меня не компилируется без
#include но в примере он не указан.
В примерах в литературе (и гораздо более сложных, чем показано) достаточно часто требуемые #include не указываются – считается, что вы их впишете сами в необходимом количестве.
Конкретно то, какие требуются #include, может меняться в зависимости от операционной системы и компилятора … а далеко не у всех (к счастью) MS VisualStudio как у вас.
А как использовать возвращенное функцией strcmp число?
if( 0 == strcmp( str1, str2 ) ) /* строки совпадающие*/
else /* не совпадают */
Другие возвращаемые значения (0) означают лексографическое упорядочение строк str1 и str2 … но для этого нужно представлять, что такое лексографический порядок.
В предпоследнем примере не хватает #include . Кодеблокс послал…