У цій статті я опишу методику роботи з двонаправленим списком в класичному його варіанті. введення списку, висновок і сортування по природному розмаїттю та полях елементів списку. Не буду вдаватися в теорію списків – перейду до опису того, що необхідно зробити для вирішення даного завдання, і по ходу справи опишу чому саме так я організував роботу.
Для побудови списку нам знадобляться дві структури: одна – поля елемента списку. друга – сам елемент списку з якорями, які будуть зв'язувати елементи між собою.
Перша структура може виглядати так:
1 2 3 4 5 | struct TRecord { //В котором есть некоторые поля int x; string s; }; |
Це структура даних списку. У ній повинні міститися поля, які безпосередньо до самого списку (вірніше до його структурі ) відношення не мають, зате зберігають інформацію. ця запис – контейнер (назвемо її так).
Другий запис:
1 2 3 4 | struct TList { TRecord Rec; TList *Next, *Prev; } |
Вона вже покликана зберігати в собі елемент контейнера, в який ми спакуємо дані, і поля для зв'язку з елементами-сусідами в списку.
Для чого знадобився такий розворот на дві структури? Так буде зручніше проводити сортування. У звичайних умовах список сортується шляхом перенаправлення його полів-якорів на інші елементи (наступного і перед в даному прикладі). Тобто,. самі дані, як були в пам'яті так в тій же комірці (осередках) і залишаються, а змінюються лише покажчики на сусідів. І це звичайно добре і правильно, але складно. Чим вище складність, тим більше ймовірність нарватися на баг в програмі. Тому варто спростити програму, щоб можна було не якоря міняти, а дані місцями (як зазвичай це робиться в сортуванні масивів наприклад). Тому доцільніше дані виділити в окремий блок-структуру, щоб перетягувати їх одним оператором, а не тягати кожне поле окремо. Нижче ви побачите що мається на увазі.
Для роботи зі списком потрібні змінні голови списку і, по необходимости, хвоста:
1 | TList *Head=0, *Last=0; |
І ось так вже буде виглядати процедура наповнення списку:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | void Add(int x, string s){ //Создадим элемент TList *r = new TList; //Наполним его данными r->Rec.x = x; r->Rec.s = s; //Обнулим указатели на соседей чтоб список //не содержал мусора r->Next = 0; r->Prev = 0; //Если этот элемент не первый - сцепим его //и предыдущий элемент if (Last) { Last->Next = r; r->Prev = Last; } //И если это голова - запомним ее if (!Head) Head = r; // После чего дадим понять программе //что созданный элемент теперь будет хвостиком Last = r; } |
Її теж можна було розділити на дві: Перша створювала б елемент, друга наповнювала б його контейнер корисними даними, але це вже за смаком.
Не забуваємо про процедуру звільнення списку. Залишати сміття в пам'яті – дурний тон, навіть якщо розумна операційка сама вміє чиститься:
1 2 3 4 5 6 7 8 9 10 11 12 | void Clear(){ //Если он вообще существует if (!Head) return; //В цикле пройдем последовательно по элементам for (Last = Head->Next; Last; Last = Last->Next){ //Освобождая их соседей сзади. //т.е. убирая предыдущие delete Last->Prev; Head = Last; } delete Head; } |
процедура виведення:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | void Write(){ //Так же в цикле for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout << Last->Rec.x; } cout << endl; for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout.setf(ios_base::right); cout << Last->Rec.s; }; cout << endl; cout << endl; } |
Така велика вона через “marafeta”. Гарний висновок на екран – досить важлива опціонально програми. Тому ширину для елементів і табличний вигляд варто дотримати.
Тепер переходимо до найцікавішого – сортування списку. Процедуру сортування я розбив на дві частини, прибравши з неї умови перевірки, які аналізують потрібно сортовані елементи просувати за списком в залежності від умови. Сама ж процедура сортування виглядає так:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 | void Sort(string FieldName, string Direct){ //Сортировкой пузырьком пройдемся по элементам списка for (TList *i = Head; i; i = i->Next){ for (TList *j = Head; j; j = j->Next){ //В зависимости от указанного направления if (Condition(Direct, FieldName, i->Rec, j->Rec)){ //Произведем обмен контейнера списка TRecord r = i->Rec; i->Rec = j->Rec; j->Rec = r; } } } } |
У неї домовимося передавати опції сортування: ім'я поля, яке підлягає сортуванню, і напрямок сортування (по зростанню – по зростанню або по спадаючій – за зменшенням).
У процедурі застосована сортування бульбашкою, як найбільш ходова. У подвійному циклі відбувається виклик функції-аналізатора, яка повинна відповісти сортування, чи потрібно міняти місцями сортовані елементи чи ні. вид, прибравши умови сортування, я спростив код самої процедури сортування. Навіть якщо потрібно буде додавати якісь ще умови або поля, саму сортування вже не доведеться чіпати.
Функція аналізатор виглядає так:
1 2 3 4 5 6 7 | bool Condition(string Direct, string FieldName, TRecord a, TRecord b){ return (Direct == "asc" && FieldName == "x" && a.x > b.x) || (Direct == "desc" && FieldName == "x" && a.x < b.x) || (Direct == "asc" && FieldName == "s" && a.s < b.s) || (Direct == "desc" && FieldName == "s" && a.s > b.s) ; } |
вона виконує 4 умови:
- Если по зростанню – за зростанням, і сортируемое поле – х:
- Если по спадаючій – за зменшенням, і поле той же
- Если по зростанню – за зростанням, але сортується друге поле, строковое
- Если по спадаючій – по спадаючій з строковим полем
У кожному з умов відповідно проводиться порівняння “больше” или “меньше” в залежності від заданих параметрів сортування. Таким чином ця функція відповідає процедурі сортування, як їй чинити з елементами. В цілому це і є весь алгоритм сортування двонаправленого списку.
Збираємо описане вище в одну програму і дописуємо функцію main():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 | #include<iostream> #include<string> using namespace std; struct TRecord { //В котором есть некоторые поля int x; string s; }; struct TList { TRecord Rec; TList *Next, *Prev; }; TList *Head; TList *Last; void Add(int x, string s){ //Создадим элемент TList *r = new TList; //Наполним его данными r->Rec.x = x; r->Rec.s = s; //Обнулим указатели на соседей чтоб список //не содержал мусора r->Next = 0; r->Prev = 0; //Если этот элемент не первый - сцепим его //и предидущий элемент if (Last) { Last->Next = r; r->Prev = Last; } //И если это голова - запомним ее if (!Head) Head = r; // После чего дадим понять программе //что чозданный элемент теперь будет хвостиком Last = r; } void Clear(){ //Если он вообще существует if (!Head) return; //В цикле пройдем последовательно по элементам for (Last = Head->Next; Last; Last = Last->Next){ //Освобождая их соседей сзади. //т.е. убирая предидущие delete Last->Prev; Head = Last; } delete Head; } void Write(){ //Так же в цикле for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout << Last->Rec.x; } cout << endl; for (Last = Head; Last; Last = Last->Next){ //выводим на экран элементы списка cout.width(10); cout.setf(ios_base::right); cout << Last->Rec.s; }; cout << endl; cout << endl; } bool Condition(string Direct, string FieldName, TRecord a, TRecord b){ return (Direct == "asc" && FieldName == "x" && a.x > b.x) || (Direct == "desc" && FieldName == "x" && a.x < b.x) || (Direct == "asc" && FieldName == "s" && a.s < b.s) || (Direct == "desc" && FieldName == "s" && a.s > b.s) ; } void Sort(string FieldName, string Direct){ //Сортировкой пузырьком пройдемся по элементам списка for (TList *i = Head; i; i = i->Next){ for (TList *j = Head; j; j = j->Next){ //В зависимости от указанного направления if (Condition(Direct, FieldName, i->Rec, j->Rec)){ //Произведем обмен контейнера списка TRecord r = i->Rec; i->Rec = j->Rec; j->Rec = r; } } } } int main() { setlocale(LC_ALL, "Russian"); //Наполняем список Add(rand() % 100, "Иванов"); Add(rand() % 100, "Петров"); Add(rand() % 100, "Сидоров"); Add(rand() % 100, "Бородач"); //Крутим список так и сяк cout << "Исходный список:" << endl; Write(); cout << "x (A->Z):" << endl; Sort("x", "asc"); Write(); cout << "x (Z->A):" << endl; Sort("x", "desc"); Write(); cout << "s (A->Z):" << endl; Sort("s", "asc"); Write(); cout << "s (Z->A):" << endl; Sort("s", "desc"); Write(); //Освобождаем список Clear(); cin.get(); return 0; } |
Зверніть увагу: Я словами вказую, як сортувати список, по якому полю і в якому порядку.
Результат:

Про другому методі сортування списку шляхом перезацепленія якорів можете почитати на programmersforum
На прохання колег по сайту (які звичайно ж правильно помітили) варто хоча б коротко згадати про принади C ++ і STL. Маю на увазі клас list, який власне уособлює списки (двонаправлені). посил простий: Все, що потрібно для роботи зі списком вже зробили. По хорошому, програмісту, працюючому зі списками, звичайно ж варто в побутових випадках обирати для роботи STL.
Опишу невеликий код із застосуванням цього контейнера, як альтернатива тому, що описано вище:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <list> #include <string> #include <iostream> using namespace std; //Опишем структуру данных элемента struct TData{ int i; string name; }; //Функцию, которая будет выступать "предикатом" //в сортировке bool Condition(TData &a, TData &b){ return a.i<b.i; } int main() { //"Создадим" переменку списка, тип елементов укажем //в <>. В данном случае это список TData list<TData> l; //Постепенно добавим элементы в конец списка TData d; d.i = 1; d.name = "1"; l.push_back(d); d; d.i = 20; d.name = "2"; l.push_back(d); d; d.i = 36; d.name = "3"; l.push_back(d); d; d.i = 4; d.name = "4"; l.push_back(d); /*И вызовем функцию сортировки, передав ей предикат Предикат - функция, принимающая два параметра, которые в ней будут сравниваться. */ l.sort(Condition); //После сортировки выведем список на экран использовав //специально предназначенный для прохода по его элементам //итератор list<TData>::iterator it; for (it = l.begin(); it != l.end(); it++){ d = *it; cout << d.i << '\t' << d.name << endl; } l.clear(); cin.get(); return 0; } |
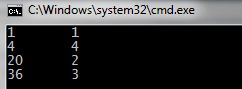
Якщо завдання дозволяє використовувати STL – используйте. Рішення виявиться надійніше і не буде трати часу на винаходи свого механізму зберігання списків.
Вибір з цих двох методів варто робити в залежності від кількості корисних даних, що вводяться в елемент списку. Якщо це пара десятка полів з числами або невеликими рядками, то найпростіший спосіб, як раз – переміщення контейнера з корисними даними (як тут). Якщо ж елементи списку мають величезний розмір, то швидше буде виконуватися методика перестановки якорів (зміни останній і наступного для перезацепленія елемента до іншого елементу). У будь-якому випадку вибір за програмістом.
Це круто, але це ваш алгоритм замінено тільки поле даних в вузлах. Якщо вам потрібно зробити велику роботу, вам потрібно замінити покажчики:
Сортування недійсними(вузол *&топ, вузол *&кінець) {
if (топ && топ->наступного) {
Вузол * ток = Вгору;
Вузол * перед = nullptr;
Вузол * TMP = nullptr;
BOOL прапор = брехня;
for (int i = 0; я поруч) {
TMP = current->наступного;
if (current->дані > tmp->дані) {
прапор = істина;
current->наступна = tmp->наступного;
tmp->Наступного = ток;
if (попередня)
prev->наступна = TMP;
tmp->перед = перед;
перед = TMP;
if (струму == Вгору)
Top = TMP;
if (!current->наступного)
End = ток;
}// якщо кінець
else {
перед = ток;
ток = current->наступного;
}
}// Кінець в той час як
if (!прапор)
break;
else {
ток = Вгору;
перед = nullptr;
прапор = брехня;
}
}// для кінця
}
else
cout << "\nNo entries for sorting\n";
}
Azizjan, почитай уважніше статтю. Посилання на метод, де дані залишаються на своєму місці я давав в реченні
“Про другому методі сортування списку шляхом перезацепленія якорів можете почитати на programmersforum”
Упевнений що новачкам корисно знати і такий і такий метод.
Є код готовий?