, strcat (), strcpy (), strcmp ()") После того, как мы с вами познакомились со строками и символьными массивами в C++, рассмотрим самые распространённые функции для работы с ними. Урок будет полностью построен на практике. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, как они устроены. К стандартным функциям библиотеки cstring относятся:
После того, как мы с вами познакомились со строками и символьными массивами в C++, рассмотрим самые распространённые функции для работы с ними. Урок будет полностью построен на практике. Мы будем писать собственные программы-аналоги для обработки строк и параллельно использовать стандартные функции библиотеки cstring (string.h – в старых версиях). Так вы примерно будете себе представлять, как они устроены. К стандартным функциям библиотеки cstring относятся:
- strlen() – подсчитывает длину строки (количество символов без учета \0);
- strcat() – объединяет строки;
- strcpy() – копирует символы одной строки в другую;
- strcmp() – сравнивает между собой две строки .
Это конечно не все функции, а только те, которые мы разберём в этой статье.
strlen() (от слова length – длина)
Наша программа, которая подсчитает количество символов в строке:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
Для подсчёта символов в строке неопределённой длины (так как вводит её пользователь), мы применили цикл while – строки 13 – 17. Он перебирает все ячейки массива (все символы строки) поочередно, начиная с нулевой. Когда на каком-то шаге цикла встретится ячейка ourStr [amountOfSymbol], которая хранит символ \0, цикл приостановит перебор символов и увеличение счётчика amountOfSymbol.
Так будет выглядеть код, с заменой нашего участка кода на функцию strlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
Как видите, этот код короче. В нем не пришлось объявлять дополнительные переменные и использовать цикл. В выходном потоке cout мы передали в функцию строку – strlen(ourStr). Она посчитала длину этой строки и вернула в программу число. Как и в предыдущем коде-аналоге, символ \0 не включен в общее количество символов.
Результат будет и в первой программе и во второй аналогичен:
 в C++")
strcat() (от слова concatenation – соединение)
Программа, которая в конец одной строки, дописывает вторую строку. Другими словами – объединяет две строки.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
По комментариям в коде должно быть всё понятно. Ниже напишем программу для выполнения таких же действий, но с использованием strcat(). В эту функцию мы передадим два аргумента (две строки) – strcat(someText1, someText2); . Функция добавит строку someText2 к строке someText1. При этом символ '\0' в конце someText1 будет перезаписан первым символом someText2. Так же она добавит завершающий '\0'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Реализация объединения двух строк, используя стандартную функцию, заняла одну строчку кода в программе – 14-я строка.
Результат:

На что следует обратить внимание и первом и во втором коде – размер первого символьного массива должен быть достаточным для помещения символов второго массива. Если размер окажется недостаточным – может произойти аварийное завершение программы, так как запись строки выйдет за пределы памяти, которую занимает первый массив. Например:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
В этом случае, строковая константа “Учите С++ c нами!” не может быть записана в массив someText1. В нём недостаточно места, для такой операции.
Если вы используете одну из последних версий среды разработки Microsoft Visual Studio, возможно возникновение следующей ошибки: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” Так происходит потому, что уже разработана новая более безопасная версия функции strcat – это strcat_s.
Она заботится о том, чтобы не произошло переполнение буфера (символьного массива, в который производится запись второй строки). Среда предлагает вам использовать новую функцию, вместо устаревшей. Почитать больше об этом можно на сайте msdn. Подобная ошибка может появиться, если вы будете применять функцию strcpy, о которой речь пойдет ниже.
strcpy() (от слова copy – копирование)
Реализуем копирование одной строки и её вставку на место другой строки.
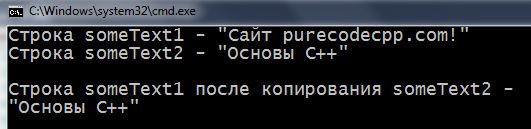
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Применим стандартную функцию библиотеки cstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Пробуйте компилировать и первую, и вторую программу. Увидите такой результат:
strcmp() (от слова compare – сравнение)
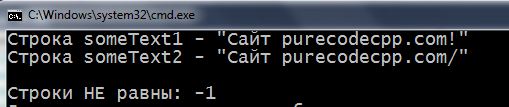
Эта функция устроена так: она сравнивает две Си-строки символ за символом. Если строки идентичны (и по символам и по их количеству) – функция возвращает в программу число 0. Если первая строка длиннее второй – возвращает в программу число 1, а если меньше, то -1. Число -1 возвращается и тогда, когда длина строк равна, но символы строк не совпадают.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
 Программа с strcmp():
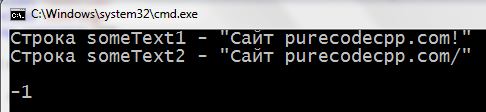
Программа с strcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Делитесь в социальных сетях нашими статьями со своими знакомыми, которые так же изучают основы программирования на языке С++.
while (true) // запускаем бесконечный цикл
{
someText1[count] = someText2[count]; // копируем посимвольно
if (someText2[count] == ‘\0’) // если нашли \0 у второй строки
{
break; // прерываем цикл
}
count++;
}
Мне не понятно куда делась остальная часть строки “Сaйт purecodecpp.com!” ,
если по идее должно получиться так: Основы С++pp.com.
Мы копируем посимвольно меньшую строку в большую, так почему остаток someText1 удаляется?
Потому, что мы копируем не меньшую в большую, а вторую в первую. И когда подойдет ‘\0’ во второй строке он тоже перезапишется в первый массив. Далее, когда будет считываться первый массив, то этот ноль и покажет конец строки и не важно, что там было за ним записано. Это будет конец строки.
#include
#include
using namespace std;
int main()
{
setlocale(LC_ALL, “rus”);
char string_Array_1[] = “Вася, ты что, устал?”;
char string_Array_2[] = “Вася, ты что, устал!”;
cout << "Первая строка – \"" << string_Array_1 << "\"\n";
cout << "Вторая строка – \"" << string_Array_2 << "\"\n";
cout << "=====================================================\n\n";
cout << "Если строки идентичны и по символам и по количеству, то: 0\n";
cout << "Если первая строка длиннее второй, то: +1\n";
cout << "Если первая строка короче второй, то: -1\n";
cout << "Если длина строк равна, но символы не совпадают, то: -1\n";
cout << "=====================================================\n\n";
cout << "В приведенном случае получился ответ: " << strcmp(string_Array_1 , string_Array_2);
cout << endl << endl;
return 0;
}
Получатся:
Первая строка – "Вася, ты что, устал?"
Вторая строка – "Вася, ты что, устал!"
==========================================================
Если строки идентичны и по символам и по количеству, то: 0
Если первая строка длиннее второй, то: +1
Если первая строка короче второй, то: -1
Если длина строк равна, но символы не совпадают, то: -1
===========================================================
В приведенном случае получился ответ: 1
Не могу понять, почему 1, если в концах строк разные символы: ? и !
Интересный баг в этом коде.
Скопировал, сделал два одинаковых текста “Вася, ты что, устал!” в char string_Array_1[] и char string_Array_2[] и проверил:
1. Пока строки одинаковы то всё GOOD!!!
2. Если первую строку сделать длиннее то получаю ” -1 ” (инвертировано).
3. Если первую строку сделать короче то получаю ” 1 ” (инвертировано).
Дальше интереснее.
4. Если в первой строке в слове ” устал ” букву ” у ” поменять на ” т ” то получаю ” -1 ”
5. Если в первой строке в слове ” устал ” букву ” у ” поменять на ” ф ” то получаю ” 1 ”
6. Если во второй строке в слове ” устал ” букву ” у ” поменять на ” т ” то получаю ” 1 ”
7. Если во второй строке в слове ” устал ” букву ” у ” поменять на ” т ” то получаю ” -1 ”
Слово ” устал ” я взял для примера. Букву ” у ” я менял на предыдущую и следующую в алфавите. Это работает с любой заменой букв ( ” а ” и ” я ” я не смог поменять).
Это не баг (как я думал). Это связано с кодировкой ASCII. Саму кодировку ASCII можно загуглить. Вот и выходит что “у” по этой кодировке больше “т” и меньше “ф”
Получается, что ‘?’ длиннее чем ‘!’
Это так???
Чем больше код символа в таблице ASCII тем “длиннее”.
“B” длиннее “А”, а “D” длиннее “B”.
Знаков препинания это тоже касается.
У “!” код 33, а у “?” код 63, значит ? > !
Да, немного разобравшись я понял (догадался) что тут идёт привязка к кодировке ASCII