Достаточно часто на практике требуется контролировать только принадлежность тех или иных объектов к некоторому подмножеству. Такие коллекции и в классической математике называются множество, к которому конкретный объект может или принадлежать, или нет. И библиотека STL предоставляет такой вид контейнеров, который так и называется — set<> (множество).
Каждый элемент контейнера set<> содержит только значение ключа (не пару, как для map<>), поэтому такой тип контейнера очень эффективно реализует операцию проверки наличия значения в наборе. Этот контейнер предоставляет много общих методов в сравнении с map<>, хотя они здесь имеют некоторые вырожденные качества (и порой бесполезные):
Операция вставки (метод insert()) нового значения ключа к множеству возвращает пару типа <итератор, bool> (точно, как для map<>). В этой паре второй компонент (second, типа bool) указывает на успешность операции: если это true, то первый компонент возвращаемого результата (first) даёт итератор нового добавленного элемента. Но это достаточно бессмысленное возвращаемое значение: если возвращается true, то новое значение успешно добавлено к множеству, если же возвращается false, то оно уже присутствует в множестве ранее — в обоих случаях конечное состояние множества будет идентичным (поэтому на практике возвращаемое значение insert() обычно даже не проверяют … а многие и не знают, что там вообще предусмотрено возвращаемое значение вообще);
Для этого контейнера реализован метод count() (как для multimap<>), но, поскольку значение ключа может присутствовать в множеств только в единичном экземпляре, метод count() может возвратить только 0, если такое значение отсутствует, и 1 когда такое значение присутствует.
Для контейнера реализован метод found(), который возвращает итератор элемента, если значение найдено, и итератор со значением end() если значение отсутствует в множестве.
Для демонстрации сказанного создадим приложение, которое N раз (параметр, задаваемый в команде запуска приложения) в цикле генерирует псевдослучайное число в фиксированном диапазоне [0…lim] и помещает его в множество. Понятно, что при возрастании N больше чем lim (а тем более при N намного больше lim), каждое число диапазона [0…lim] будет генерироваться всё большее и большее число раз:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | #include <iostream> #include <cstdlib> #include <iomanip> #include <cmath> #include <set> using namespace std; int main( int argc, char **argv ) { unsigned lim = 30, n = argc > 1 ? atoi( argv[ 1 ] ) : lim; set<unsigned> rnd; for( unsigned i = 0; i < n; i++ ) { rnd.insert( (unsigned)nearbyint( (float)rand() / RAND_MAX * ( lim - 1 ) ) ); } cout.fill( '0' ); for( unsigned i = 0; i < lim; i++ ) { if( 1 == rnd.count( i ) ) cout << setw( 2 ) << i << " "; else cout << "- "; } cout << endl; for( auto i = rnd.begin(); i != rnd.end(); i++ ) cout << setw( 2 ) << *i << " "; cout << endl; } |



Другим близким типом контейнера является multiset<>, позволяющее каждому значению ключа быть не уникальным, и находиться в множестве сколько угодно раз. Эти два контейнера (set<> и multiset<>) настолько подобные, что в показанном выше приложении мы заменим всего 2 строчки (метод count() для multiset<> возвращает число вхождений значения в множество):
1 2 3 4 | ... multiset<unsigned> rnd; ... if( rnd.count( i ) > 0 ) cout << setw( 2 ) << i << " "; |
Но поведение приложения радикально меняется (для сравнения рядом показаны результаты 2-х приложений в идентичных условиях):
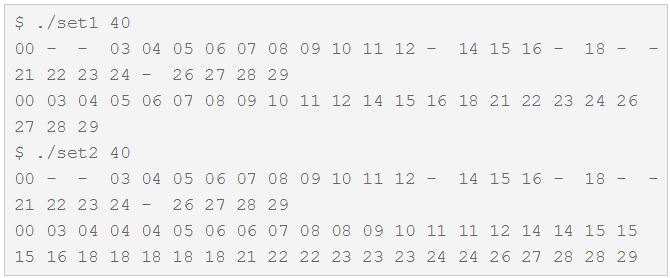
Видим, что для мультимножества значения 1, 2, 13, 17… отсутствуют в контейнере, а значение 18, например, присутствует в нём 5 раз.