Мы рассмотрели простой пример использования map<> для подсчёта вхождения отдельных литер в текст. Для этой цели мы использовали контейнер map<>. Но библиотека STL нам предоставляет и другой (близкий) тип контейнера — это multimap<>, который допускает наличие многих элементов (pair<>) в своём составе с одинаковыми значениями ключей.
Естественно, что основные правила функционирования multimap<> изменятся (по сравнению с map<>). Для такого контейнера будут следующие отличия в поведении:
Содержит упорядоченные пары <ключ,значение>, где ключ и значение могут принадлежать к произвольным типам;
Элементы с любыми значениями ключа не должны быть уникальными, в упорядоченной последовательности элементов (по ключу) такие эквивалентные элементы представлены, как разные элементы, и располагаются они друг за другом;
Поскольку ключи могут совпадать, то операция добавления новой пары в таблицу (метод insert()) всегда успешна. Поэтому нет смысла возвращать результат такой операции: возвращаемое значение — void;
Поскольку теперь в контейнере может находиться много элементов с равными ключами, то вводится дополнительный метод count(). Он получает параметром значение ключа, возвращает число вхождений элементов, имеющих такой ключ, в контейнер;
Операции удаления (метод erase()) с указанием ключа удаляемого элемента удаляет все сразу элементы с совпадающими ключами;
Посмотрим как multimap<> справится с предыдущей задачей. Вот текстовые файлы для тестирования программы:
| 30 Brother_And_Sister | 11 Humpty-Dumpty | 34 Jabberwock |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | #include <iostream> #include <sstream> #include <map> using namespace std; int main(int argc, char **argv) { multimap< char, int > alphabet; while (cin) { string line; getline(cin, line); if (line.empty()) continue; istringstream ist(line); char let; while ((let = ist.get()) && let != EOF) alphabet.insert(pair< char, int >(let, 1)); } cout << "alphabet size = " << alphabet.size() << endl; for (char c = 'a'; c <= 'z'; c++) cout << c << "(" << alphabet.count(c) << ") "; cout << endl; alphabet.erase('a'); cout << "alphabet size = " << alphabet.size() << endl; for (char c = 'a'; c <= 'z'; c++) cout << c << "(" << alphabet.count(c) << ") "; cout << endl; cout << "alphabet size = " << alphabet.size() << endl; } |
Как и в предыдущем примере, используется несколько громоздкий ввод символов из потока, содержащего текст во много строк. Это связано с тем, что а). хотелось бы читать и символы пробела тоже как символы, а не как разделители и б). можно было бы просто последовательно читать символы из cin с последующим исключением переводов строки. Но в показанном варианте хотелось бы сохранить независимость от используемой операционной системы (различие так называемого DOS и UNIX перевода строки). В остальной части код стал много короче и проще.
Результат того, что мы получили, показан ниже (рядом повторено для сравнения то же действие, выполняемое map<>):
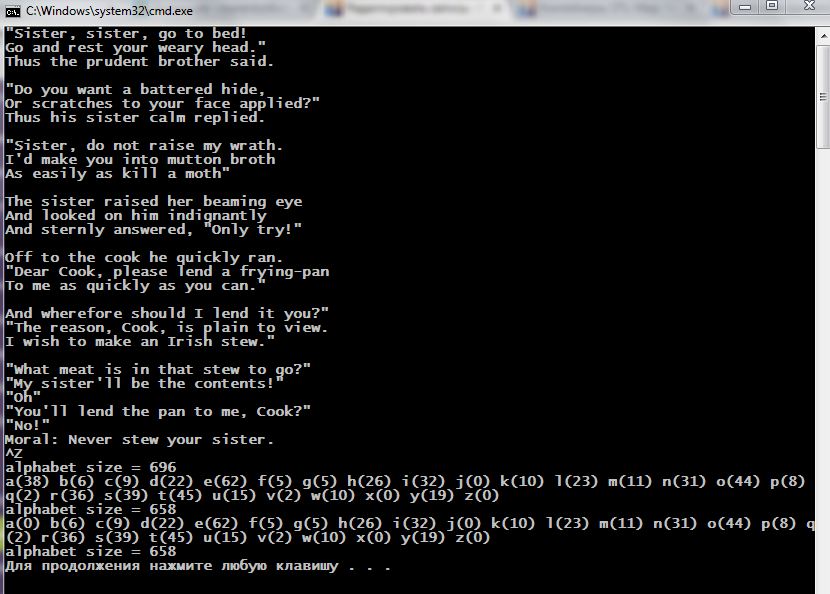
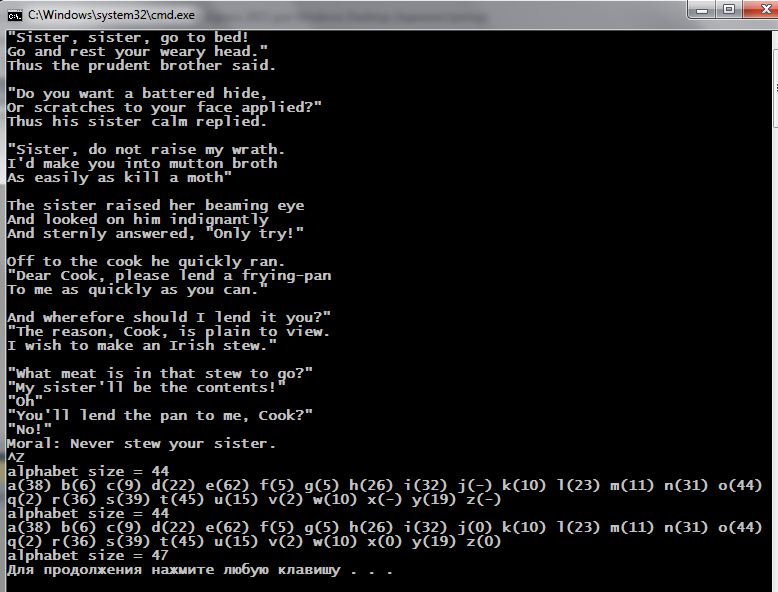
Обратим внимание на то, как единичным оператором удаления alphabet.erase( ‘a’ ) мы удалили из таблиц 38 элементов, определяющихся ключом ‘a’. Откуда взялся размер size() в 696 элементов?

(Показанная форма команды wc вычисляет в операционной системе Linux число строк в файле. Команда ls выводит длину файла, т.е. число отдельных байт, символов в файле. В Windows вы можете попытаться добиться некоторого подобного результата используя команду dir.)
Если мы из общего числа символов (длины в байтах) вычтем число строк (переводов строк) в файле, то мы и получим эту цифру: 726 – 30 = 696. Таким образом, для каждого символа входного потока был создан отдельный элемент таблицы, например, с ключом ‘s’ было 39 таких элементов.
Всё, ранее сказанное относительно контейнера map<> (кроме алгоритма помещения и выборки) в полной мере относится и к multimap<>, например, требование сравнимости ключей и то, как определить или переопределить операцию сравнения.
gi5idp