Мы рассмотрели простой пример использования map<>, но использование такого контейнера уже существенно сложнее последовательных контейнеров. Контейнер map<> (таблица, отображение):
Содержит упорядоченные пары <ключ,значение>, где ключ и значение могут принадлежать к произвольным типам. Для типа ключа должна быть либо предопределена, либо определена пользователем операция сравнения;
Элементы с любым значением ключа должны быть уникальны;
Попытка добавить (метод insert()) к таблице новую пару с уже имеющимся значением ключа завершится неудачей;
Операция добавления новой пары в таблицу возвращает пару типа <итератор, bool>, у которой второй компонент (логический second) указывает на успешность операции. Если он true, то первый компонент возвращаемого результата (first) даёт итератор добавленного элемента. Если же он false, то возвращается итератор существующего элемента с тем же ключом;
Операции индексации таблицы ( [ ] или at() ) требуют в качестве ключа любое значение типа, определённого для ключа;
Операция индексации at(), при задании ключа-параметра, отсутствующего в составе элементов таблицы, вызывает исключение;
Напротив, операция индексации [ ], при задании ключа-параметра, отсутствующего в составе элементов таблицы, исключение не вызывает. (наоборот, даже если индексация запрошена только по чтению, добавляет к контейнеру новый элемент с требуемым значением ключа, но с нулевым полем значения);
Эти определения могут показаться замысловатыми, но всё разъяснит последующий пример.
Прежде представления примера, мы должны подготовить некоторые файлы тестовых данных для работы с ассоциативными контейнерами. Работа именно с объёмными символьными данными демонстрирует всю мощь использования таблиц STL. В качестве текстовых данных мы подготовим файлы, содержащие англоязычные оригинальные тексты нескольких стихотворений Льюиса Кэрола.
Ничуть не сложнее использовать и русскоязычные тексты, но в этом случае вам придётся работать с классами wstring и локализованными преобразованиями, что только увеличит громоздкость примеров без увеличения их содержательности.
Вам предоставлено несколько текстов разной длины для обстоятельного тестирования кодов этой и последующих частей изложения (файлы показаны с подсчётом числа строк их текстов). Здесь, например, Humpty-Dumpty.txt — это текст из части VI Humpty-Dumpty «Алиса в зазеркалье».
| 30 Brother_And_Sister | 11 Humpty-Dumpty | 34 Jabberwock |
А Jabberwock.txt — это текст из части VI Humpty-Dumpty «Алиса в зазеркалье» — известное в русскоязычном варианте стихотворение (в исполнении В.С.Высоцкого): О бойся Бармаглота, сын! Он так свиреп и дик…
В нашем оригинале (авторском, англоязычном, для отладки – файл Jabberwock.txt) этот текст выглядит так:
 | Twas brillig, and the slithy toves Did gyre and gimble in the wabe: All mimsy were the borogoves, And the mome raths outgrabe. «Beware the Jabberwock, my son! |
Текст, безусловно, синтаксически сложный, что делает его прекрасным материалом для отладки приложений. Вам предоставляется отменный материал для дальнейших самостоятельных экспериментов!
Итак … наше приложение будет подсчитывать число вхождений каждой из литер алфавита в предлагаемый текст, используя map<>:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 | #include <iostream> #include <sstream> #include <map> using namespace std; int main(int argc, char **argv) { map< char, int > alphabet; while (cin) { string line; getline(cin, line); if (line.empty()) continue; istringstream ist(line); // строка как поток чтения char let; while ((let = ist.get()) && let != EOF) { // посимвольно pair< map< char, int >::iterator, bool > ret; ret = alphabet.insert(pair< char, int >(let, 1)); // если неудача - буква уже присутствует: if (!ret.second) ret.first->second++; } } cout << "alphabet size = " << alphabet.size() << endl; // если буква найдена - вывести её: for (char c = 'a'; c <= 'z'; c++) { cout << c << "("; try { cout << alphabet.at(c); } catch (exception const& e) { cout << '-'; } cout << ") "; } cout << endl; cout << "alphabet size = " << alphabet.size() << endl; for (char c = 'a'; c <= 'z'; c++) { cout << c << "(" << alphabet[c] << ") "; } cout << endl; cout << "alphabet size = " << alphabet.size() << endl; } |
Контейнер map<> — не самый лучший вариант для поставленных целей: при нахождении новой литеры в тексте мы попытаемся добавить её в качестве ключа таблицы, но если эта литера уже присутствует в таблице, то попытка завершится неудачей. В этом случае, после неудачи, мы, по индексу ключа, просто инкрементируем число его вхождений. И вот что мы поучаем:
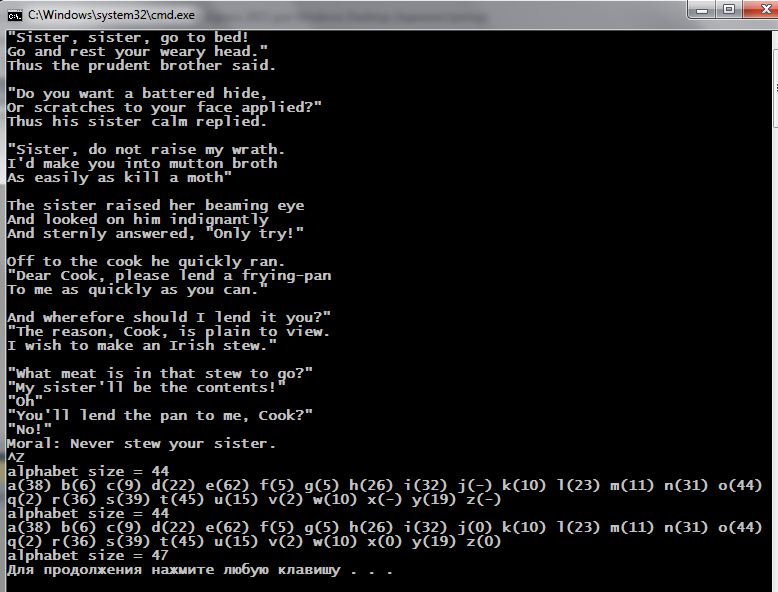
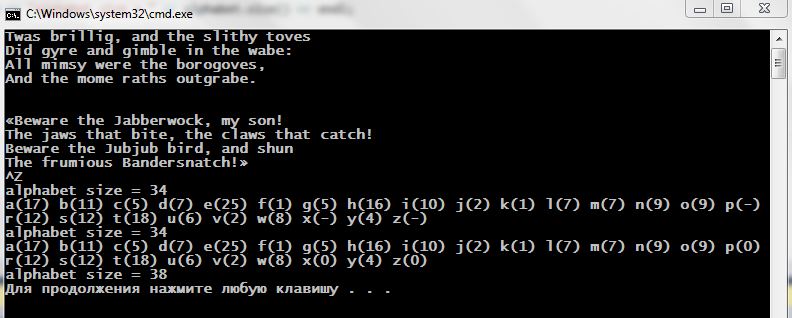
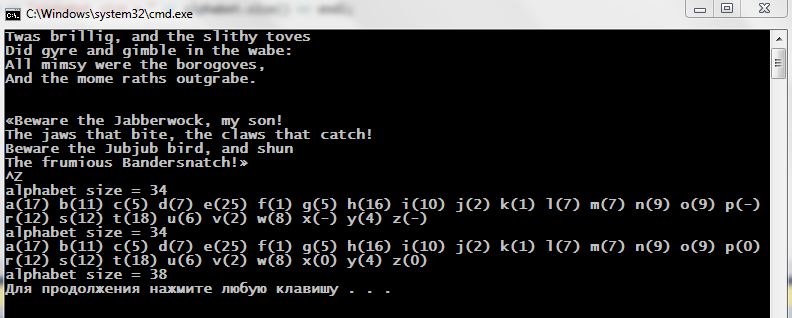
Обратите внимание как увеличился размер таблицы после того, как в ней был индексированием [ ] осуществлён поиск (по чтению!) отсутствующих ключей (‘q’, ‘z’, ‘x’).
Возникает вопрос: почему вы видим в качестве size() такие значения как 44, 47, 50, 52, если мы наблюдаем только раскладку по повторяемости 26 символов от ‘a’ до ‘z’? Ответ прост: потому что в текст могут входить символы пробела, знаков препинания, заглавных литер, которых мы не наблюдаем в выдаче теста.
Если воспользоваться такой новой возможностью стандарта C++11, как списки инициализации, создание и инициализация таблицы может выглядеть гораздо проще:
1 2 3 4 5 6 7 8 9 10 11 12 | #include <iostream> #include <map> using namespace std; int main(int argc, char **argv) { map< int, char > nums = { { 1, 'a' },{ 3, 'b' },{ 5, 'c' },{ 7, 'd' } }; for (auto i = nums.begin(); i != nums.end(); i++) cout << i->first << "->" << i->second << " "; cout << endl; } |
Естественно, всё это станет компилироваться только при указании опций компилятора для использования стандарта C++11:
Из сказанного уже должно быть понятно, что в качестве ключа поиска в таблице может использоваться любой тип, при обязательном условии, что для него либо определена естественная операция сравнения (int, float, string, …), либо мы сами определим такую пользовательскую функцию, которая будет использоваться для сравнений. Несколько способов сделать это показаны ниже:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | #include <iostream> #include <map> using namespace std; template< typename Map > void print_map(Map& m) { cout << "{ "; for (auto& p : m) // перебор всей таблицы cout << p.first << ':' << p.second << ' '; cout << "}" << endl; } // функция сравнения: bool great(int lhs, int rhs) { return lhs > rhs; } // функтор сравнения: struct classcomp { bool operator()(const int& lhs, const int& rhs) const { return lhs > rhs; } }; int main(int argc, char **argv) { // таблица, сравнение по умолчанию map< int, int, less< int > > ml = { { 1, 2 },{ 2, 3 },{ 3, 4 },{ 4, 5 } }; print_map(ml); // таблица с нашей great() функцией сравнения map< int, int, bool(*)(int, int) > mg1(great); mg1.insert(ml.begin(), ml.end()); print_map(mg1); // таблица с классом-функтором map< int, int, classcomp > mg3(ml.begin(), ml.end()); print_map(mg3); } |
Здесь мы, сменив функцию сравнения ключей, изменили порядок сортировки элементов при размещении их в таблице. (Во 2-м варианте используется функциональный объект, функтор, работе с которыми будет посвящена отдельная часть нашего рассмотрения.)
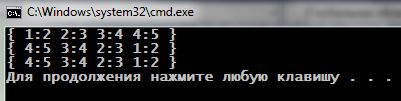
Получилась интересная и понятная статья.
А будет продолжение – удаление, замена, contains, поиск по ключу и др.?
Обязательно будет.
Это какая часть? 7-я?
Так уже готовых есть 16.
Ожидайте.
Спасибо за невероятный труд и помощь в изучении С++, однако теперь пошли непонятки. До сих пор нормально было в течении уроков. Прежде чем что-то писать в качестве примера, нужно объяснить что это. Иначе, если пример непонятен, то толка нет от учебы, только практика запоминается и усваивается. Ладно неупомянутый символ ^Z (ctrl-Z) удается заметить на картинке результата работы программы со стихами в консоли и хорошо, если читатель знает, что он означает конец файла для консоли, без его ввода программа не работала бы (цикл не завершился бы). Но в следующем примере пошло еще тяжелее .
1) функторы не изучались, что это неизвестно и пример понять невозможно, потому что там написано bool operator(), а мы так не делали ни разу, после слова operator перед скобками всегда писали знак оператора (+, -, …). Хорошо, можно подумать, что наверное подразумевается тот знак, который находится в выражении после return. А в следующих строчках еще более непонятно:
2) map< int, int, less > – это что? Было изучено что map состоит из пары ключ-значение, а less что здесь делает и что такое less вообще непонятно. По виду можно предположить что это некий шаблонный класс с параметром int. Но скорее всего он указывает порядок сортировки по значению ключа в убывании или возрастании данных в контейнере map.
3) map mg1(great); – это непонятно. Можно догадываться в том или ином направлении, только догадки мало помогают в таких делах. mg1(great) – это конструктор с параметром функцией? Такой конструктор для map не изучался, и не только для map.
4) map – примерно то же самое.
Подводя итог можно сказать, что это за третий параметр появился при объявлении объекта-контейнера map внутри угловых скобок? Видно по контексту, что он задает порядок сортировки по значению ключа, но достоверной информации нет.
2) map< int, int, less >
3) map mg1(great);
код в комментах отображается не полностью. Жаль.
Вроде разобрался благо интернет под рукой.
До сих пор нормально было в течении уроков. Прежде чем что-то писать в качестве примера, нужно объяснить что это.
1. Просто “до сих пор” было только потому, что до сих пор было только цветочки – затрагивались только самые-самые элементарные понятия C++. Сейчас описываются уже достаточно продвинутые средства.
2. Из матлингвистики, теории языков программирования известно, что любой язык программирования не может быть описан строго последовательно, и поэтому описываются они рекурсивно: используя конструкции, которые ещё не описывались ранее. Это теория.
Если что-то вам категорически не понятно – пропустите это, вы вернётесь к нему позже, при “2-м проходе”, когда оно уже станет понятным.