,strcatp ()istrcpytrcmp") After, as we are acquainted with strings and character arrays in C ++, look at the most common functions for working with them. The lesson will be fully built in practice. We will write their own programs-analogues for the treatment of strings and parallel to the use of standard library functions cstring (string.h – in older versions). So you're about to present itself, how they work. The standard library functions cstring include:
After, as we are acquainted with strings and character arrays in C ++, look at the most common functions for working with them. The lesson will be fully built in practice. We will write their own programs-analogues for the treatment of strings and parallel to the use of standard library functions cstring (string.h – in older versions). So you're about to present itself, how they work. The standard library functions cstring include:
- strlen() – calculates the length of the string (the number of characters excluding \0);
- strcat() – it combines strings;
- strcpy() – copies the symbols of one line to the other;
- strcmp() – compares two strings together .
Это конечно не все функции, а только те, which is covered at the article.
strlen() (from the word length – length)
Our program, which will calculate the number of characters in a string:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
For counting characters in a string of uncertain length (as it enters the user), we used the loop while – strings 13 – 17. It iterates through all the cells in the array (all the characters in a string) alternately, starting with zero. When at some step loop to meet BoxourStr [amountOfSymbol], that stores symbol\0, bust loop pause symbols and increase the counter amountOfSymbol.
So the code will look like, the replacement of our code section on the functionstrlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
As you can see, this short code. It did not have to declare additional variables and use a loop. The output stream cout we passed into the function string – strlen(ourStr). It is suggested that the length of the string and back to the program number. As in the previous code-analog, symbol \0 not included in the total number of characters.
The result is the program in the first and second similar:
 in C++")
strcat() (from the word concatenation – connection)
Program, which at the end of one string, appends the second string. In other words – concatenates two strings.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
By the comments in the code should be clear. Below, we write a program to perform the same actions, but using strcat(). In this feature, we will give two arguments (two strings) – strcat(someText1, someText2); . The function adds a stringsomeText2 to linesomeText1. At the same symbol '�' at the end someText1It will overwrite the first charactersomeText2. She also adds a final '�'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Realization of unification of two strings, using standard function, took one string of code in a program – 14--s a string.
Result:

What should pay attention to the first and second code– size of the first character of the array should be sufficient for the second array of characters premises. If the size is insufficient – may occur abnormal program termination, since the string recording out of memory, which occupies the first array. For example:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
In this case, a string constant“Learn C ++ c us!” It may not be written into the arraysomeText1. As there is not enough space, for such operations.
If you are using a recent version of Microsoft Visual Studio development environment, you may experience the following error:: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” This is because, that has developed a new, more secure version of the functionstrcat – this isstrcat_s.
She cares about, to avoid buffer overflow (a character array, which produced record second string). Environment offers to use the new feature, instead of outdated. Read more about this can be on the msdn website. This error can appear, if you use the functionstrcpy, which will be discussed below.
strcpy() (from the word copy – copying)
Implement copying one string and its insertion in the place of another string.
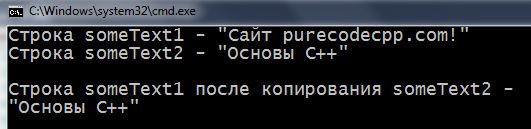
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Apply the standard function librarycstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Try to compile and first, and a second program. You will see this result:
strcmp() (from the word compare – comparison)
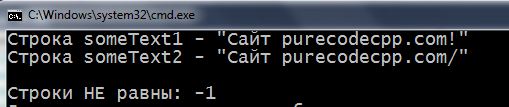
This function is designed to: she compares the two C-string character by character. If the strings are identical (and symbols and their number) – the function returns to the program number 0. If the first line is longer than a second – returns to the program number 1, and if less, then -1. The number of -1 back then, when the length of the strings is, but the characters of the strings do not match.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
 program withstrcmp():
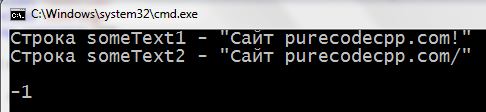
program withstrcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Share on social networks our articles with your friends, who also learn the basics of programming in C ++.
There milyard pieces, you may have missed, but we describe in great detail the obvious…
>> Program, which at the end of one string, appends the second string. In other words - it combines two lines.
So, and in other words – various shots, but the essence is not clear.
I have 2 char * string for each allocated 256 bytes.
The first recorded “hello”, second “world”.
I unite them. How many bytes I needed? 512 or 10?
Answer and go further in the text :).
Vladimir, pointers topic in this article does not rise. If we talk about character arrays (Si-strokah) size 256 bytes each, after string concatenation “hello” and ” world”, row in which the characters are finished writing world, will take 256 bytes, as well as prior to the merger.
#include#include
using namespace std;
int main()
{
setlocale(LC_ALL, "rus");
char strHello[256] = "hello"; // все ячейки после hello будут содержать символ /0
char strWorld[256] = " world";
strcat(strHello, strWorld);
cout < < strHello << endl << endl; cout << "Размер строки strHello в байтах после объединения = " << sizeof(strHello) << endl; // функция sizeof() возвращает размер в байтах, переданного ей аргумента return 0; }
strWorld string takes strHello cell line, following the characters hello (strWorld first character of the string "zatret" \0 after the 'o' character of strHello).
Working with pointers to strings, of course, better perevydelyat amount of memory required to store strings of characters, and not occupy too much space. It will turn, what is necessary 12 byte for "hello world". All in order - and we come to this :)
P.S. comments,code and an explanation is not for you, and for beginners, which will read something about what we are talking
Can I write
strcat(strHello, strHello)
?
Why?
The question is really very interesting! I have never had to think about it. At first sight, in this record is not strange. But it does not work well! :) Error states “The buffer is too small”. A friend of mine (Vitali) I said so to the question: “written documentation, what “if the function objects overlap, its behavior is not defined.” the programmer who writes so sucked into the void )) ” Well, even so continued: “It goes up one character. The function searches \0 the first line, finds, character by character and starts to glue the second row. BUT! it will glue until it finds \0 which no longer exists!
Vova, we are grateful, If you, too, will answer us on this issue.
the memory has already been allocated
Well, right comrade said, The first line copies the characters from its beginning to its end, therefore grows infinitely.
The mane is written:
Lines can not overlap, and dest must have enough space to hold the result.
In reality, there is a buffer overflow, but purely by chance it might work (the error does not come out), but the program is modified somehow unpredictable.
Dokapalis I to, that the description of this function takes mana lines 6. Just, clear all at once (and about large enough buffers, and about the intersection of the lines). You write a hundred times the same thing with different words, I do not know why xD.
>> P.S. comments,code and an explanation is not for you, and for beginners, which will read something about what we are talking.
You're writing an article about coding conventions. It seems like some of them indicates the optimal number of comments in the code. Nobody writes to each line.
Å ê in non indeksiruetsâ Poiskovik (or I'm wrong?), so just more profitable to put a description to the code after the code, not inside.
You are writing, “functions for working with strings in C ++”, actually they once were in , but in C ++ there , and old (“sishnye”) string passed in (here there and described these sorts strcat, … ). That is. I read the title and expect to read about std::string, and here… (They deceived me xD).
so no comments in the code for each line )) there are only a couple of pieces. P.S. It was written to, that you do not think if I told you all this explain. You know what – It's clear ))
With regard to the title. By name certainly can nitpick… Only if the article was about the string, it also will not name “functions for working with strings in C ++”. rather – Methods for working with strings Class string objects.
How would you call this article? Maybe the truth is better to rename.
But I read an article on…
About strcpy you brought something analogue type, i.e.. tried gash strcpy own hands, I understand correctly?
just
Not exactly xD.
The mane (standard seems too) It says that the lines do not overlap. In gcc it seems to work out fine overlapping lines, but this standard may be undefined behavior, and means in another compiler (another version of the same compiler) it may break.
I think, that on this topic better describe typical errors (с strcpy – This buffer overflow) and ways to combat.
I'd thought about crafts melkosofta, type strcpy_s. If you are writing code in visual studio, then you will hear and stopudovo warning window that, strcpy that must be replaced by a secure version – strcpy_s. That's about this thing you can write IMHO.
Look here
Well about strcpy_s and strcat_s – This was my question for you )) It turns out Now, that the question asked itself.
Interesting you have a way of communicating:
– just.
– Not exactly.
+ My questions are the same, and I ask…
Vova. I propose to communicate well, if we respect each other )
but a whole article became Godnev, code formatted least uniformly :). More fun is not enough examples, whether…
Write more :)
well you know, you not looked KVN :)
>> Vova. I propose to communicate well, if we respect each other )
“On you” whether? )
About the more correct name entries do not know anything. I'm not a fan of mikrostatey, I would write under this name, and about C-string, a string of. I have come up with some example, which would have brought a bunch of string functions, and by the functions themselves have written a very short (otnostrochnыe) comments, I would have brought them to the table. Posted to about buffer overflow – just do a common mistake when working with strings, safe-functions from Microsoft and another example of the type… “given an array of strings, it is necessary to merge it into one big string” – there would be stopped on the evaluation of the asymptotic complexity – Example gorgeous and assessment of complexity does not lie on the surface.
I do not so much ask questions, many suggest topics for the following articles (theses or to finished current).
Anyway – thank you for the constructive criticism and suggestions! It is interesting to communicate with you
About the example of the merger will explain the array of strings.
is an artifact from strcat, here you are right already written, that before you begin to merge, it replaces the symbol . But to his zanmenit, it is necessary to find. But how to find it, If the string size is not known? – iterate sequentially all line items.
If you merge 2 strings – the first length N, second – M, it will be executed N + M operations, tk. first N operations to find , M operations and then to record the contents of the second row in the first.
Although, many programmers, do not look into the documentation of operations expected M, tk. forget about the search.
Respectively, if we have an array of K lines, and so will, that the first line is too long, and the rest are very short, the complexity of the algorithm is not very small (although, because we add a short string to a long), and close to K * only, где Only – the sum of the lengths of all strings. In short, instead of the linear quadratic complexity.
But in std::string all very different, although the complexity will remain the same (about, because there are things such as memcpy, and the vector can grow in spurts) despite, that the lines of known size. think why, MB draw a new article.
A couple of lines in the protection of the author!
Vladimir, appeal to you “About the more correct name entries do not know anything” – there is nothing to find fault with the invented name, and it turns out – I do not like, but I do not know how best to… “I would write…”, “I came up to…”, ” brought to…” and t. д. and so on. But I do not write, did not invent, not brought… (If I'm too categorical and deeply wrong – share, Be kind to link to your article on the same topic). And someone wrote, invented, did. And you are now sidiete “all so smart” and criticize. I would have made a lot of good…. While someone picks and makes! I like the article and is very popular and understandable examples. The presentation much clearer than my current teacher at the university in C ++ (Another compliment to the author). Many thanks to the mastered this site rather than studies and abstracts (but sadly). Author, Thank you for your work! Do not stop there, Your efforts benefit people!
the first example of comparison about 2 lines I have not compiled without
#Example include but it is not specified.
The examples in the literature (and much more complex, than shown) frequently required #include not specified – considered, you will enter their own in the required quantity.
Specifically, the, which required #include, may vary depending on the operating system and compiler … but not all (fortunately) MS VisualStudio like you.
How to use the number returned by strcmp?
if( 0 == strcmp( str1, str2 ) ) /* string matching * /
else /* do not match */
Other return values (0) means leksograficheskoe ordering strings str1 and str2 … but it needs to represent, what leksografichesky order.
In the penultimate example is missing #include . Kodebloks sent…