,strcatp ()istrcpytrcmp") After, as we are acquainted with strings and character arrays in C ++, look at the most common functions for working with them. The lesson will be fully built in practice. We will write their own programs-analogues for the treatment of strings and parallel to the use of standard library functions cstring (string.h – in older versions). So you're about to present itself, how they work. The standard library functions cstring include:
After, as we are acquainted with strings and character arrays in C ++, look at the most common functions for working with them. The lesson will be fully built in practice. We will write their own programs-analogues for the treatment of strings and parallel to the use of standard library functions cstring (string.h – in older versions). So you're about to present itself, how they work. The standard library functions cstring include:
- strlen() – calculates the length of the string (the number of characters excluding \0);
- strcat() – it combines strings;
- strcpy() – copies the symbols of one line to the other;
- strcmp() – compares two strings together .
Это конечно не все функции, а только те, which is covered at the article.
strlen() (from the word length – length)
Our program, which will calculate the number of characters in a string:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
For counting characters in a string of uncertain length (as it enters the user), we used the loop while – strings 13 – 17. It iterates through all the cells in the array (all the characters in a string) alternately, starting with zero. When at some step loop to meet BoxourStr [amountOfSymbol], that stores symbol\0, bust loop pause symbols and increase the counter amountOfSymbol.
So the code will look like, the replacement of our code section on the functionstrlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
As you can see, this short code. It did not have to declare additional variables and use a loop. The output stream cout we passed into the function string – strlen(ourStr). It is suggested that the length of the string and back to the program number. As in the previous code-analog, symbol \0 not included in the total number of characters.
The result is the program in the first and second similar:
 in C++")
strcat() (from the word concatenation – connection)
Program, which at the end of one string, appends the second string. In other words – concatenates two strings.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
By the comments in the code should be clear. Below, we write a program to perform the same actions, but using strcat(). In this feature, we will give two arguments (two strings) – strcat(someText1, someText2); . The function adds a stringsomeText2 to linesomeText1. At the same symbol '�' at the end someText1It will overwrite the first charactersomeText2. She also adds a final '�'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Realization of unification of two strings, using standard function, took one string of code in a program – 14--s a string.
Result:

What should pay attention to the first and second code– size of the first character of the array should be sufficient for the second array of characters premises. If the size is insufficient – may occur abnormal program termination, since the string recording out of memory, which occupies the first array. For example:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
In this case, a string constant“Learn C ++ c us!” It may not be written into the arraysomeText1. As there is not enough space, for such operations.
If you are using a recent version of Microsoft Visual Studio development environment, you may experience the following error:: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” This is because, that has developed a new, more secure version of the functionstrcat – this isstrcat_s.
She cares about, to avoid buffer overflow (a character array, which produced record second string). Environment offers to use the new feature, instead of outdated. Read more about this can be on the msdn website. This error can appear, if you use the functionstrcpy, which will be discussed below.
strcpy() (from the word copy – copying)
Implement copying one string and its insertion in the place of another string.
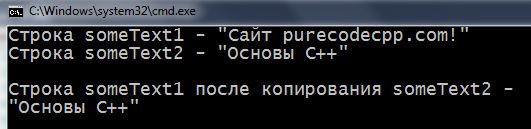
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Apply the standard function librarycstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Try to compile and first, and a second program. You will see this result:
strcmp() (from the word compare – comparison)
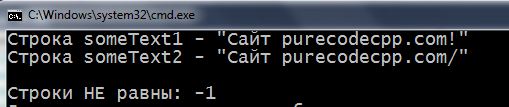
This function is designed to: she compares the two C-string character by character. If the strings are identical (and symbols and their number) – the function returns to the program number 0. If the first line is longer than a second – returns to the program number 1, and if less, then -1. The number of -1 back then, when the length of the strings is, but the characters of the strings do not match.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
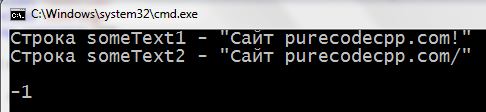
 program withstrcmp():
program withstrcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Share on social networks our articles with your friends, who also learn the basics of programming in C ++.
Hello. Tell me please, why when combine two rows and the second character array specified array length, for example
, then the second array is not combined with the first?
It is not true.
You have the result may simply be placed in someText1[].
Increase its size – what greedy?
For example: someText1[ 200 ]
Explain, you are welcome, why in Example rows association with
int count1 = 0; // for the cell where the index is stored ' 0’ first row
while (someText1[count1] != 0)
we are writing “someText1[count1] != 0” but not “someText1[count1] != ‘\0′”?
We seem to be looking for an element of a character string end with ' 0'? What does the zero?
Although I must say, I have a Koudblokse works with zero…
Because the record ' 0’ once again, and means: bytes, numerical value recorded in which equal 0.
Such records are equivalent.
Dear author!
To my mind, in the first comparison example rows directive omitted preprocessor #include
The couple can not understand
char xsmibol[2] = {wParam, ‘�’};
It works like this
————————–
And this is not working:
char xsmibol[2];
xsmibol = {wParam, ‘�’};
He speaks 17 27 C:\Users1Documentsmain1.cpp [Warning] extended initializer lists only available with -std=c++11 or -std=gnu++11
17 12 C:\Users1Documentsmain1.cpp [Error] assigning to an array from an initializer list
37 14 C:\Users1Documentsmain1.cpp [Error] expected primary-expression before ‘)’ token
What am I doing wrong ?
I think, In the first case – char xsmibol[2] = {wParam, ‘�’}; the compiler calculates the size of the string and substitutes for a place 2. In the second case -char xsmibol[2];
xsmibol = {wParam, ‘�’}; he can not fix the size of the string.
Because the array is allowed initialization a list of values ({…,…}), but not allowed assignment. This syntax rules C ++, and it does not depend on type array elements – whether it is a char array (strings), or an array of int, float array, etc..
P.S. This limitation is partly reduced in C ++ Standard 11 (2011city), but it is necessary to specify compilation options.
good afternoon. I study your lessons and tasks.
But noted a discrepancy in the results of the function strcmp.
In the case that the number of characters in two lines , but the differences between these characters result 1 or -1 depends on the sequence in which these symbols. If the first line contains symbols , are in alphabetical order than your second line of the result 1, if on the contrary the result -1. For example: string comparison “asdf” and “bsdf”will give 1, a string comparison “bsdf” and “asdf” will give -1. And also with numbers. “1234” and “2234” will give 1, and “2234” and “1234” will give -1.
Sorry, on the contrary, "1234" and "2234" will give -1, and "2234" and "1234" will give 1.
quite naturally – comparison operation is not commutative, it does not allow the permutation of operands. The same is true for the numeric values and comparing them (this is understandable): 2 > 1 – it is true, but 1 > 2 – is false.
Hello!
Tell, you are welcome, why, in the example of combining two lines using cycles, we will point out the dimension of the first string array?:
char someText1[64] = “Сайт purecodecpp.com!”;
char someText2[] = “Learn C ++ c us!”;
And if you leave a blank dimension, allowing the compiler to independently calculate this value, the consolidated text is displayed after compilation in the console, plus some random character(completely randomly), then the error window appears:
(for example, in this case, It adds a question mark:
someText1: Сайт purecodecpp.com!Learn C ++ c us!?
instead – someText1: Сайт purecodecpp.com!Learn C ++ c us!
Because pointing someText1[64] you rezerviruete by line 64 bytes of memory, although the line is written to the "Site purecodecpp.com!”, limited ' 0', It takes much less bytes (strlen(someText1)).
And when you write someText1[], compiler calculates and reserves for this line does not 64 bytes, and just enough, as needed to accommodate the specified string + end character ' 0'.
As soon as you try to perform appending someText2 in tail someText1, in the 1st case up occurs here in those 64 reserved bytes. And in the 2nd case, you immediately start writing border Memory allocated for someText1, and the result will be unpredictable – this is rough error.
Hello, I rewrote the program code of your first, launched – try… I am writing to check one word, to check whether the correct answer will give, so, the word: “summer”, It consists of 4 characters, in writing not used not spaces, no quotes, Only the letter… and program outputs:
“String “summer” состоит из 8 characters!”
…8-me? Why? :) Is not 4 symbols? Similarly, with the two words:
“summer morning”
“String “summer morning” состоит из 17 characters!”
each letter, considered as the compiler 2 symbols, space – 1 symbol. But each character has to be counted as 1… ?
I did not understand how to properly write a great text in such a way – 'F', and so on – even one letter long to write…. to not just quotes!? I can not understand something!?