,strcatp ()istrcpytrcmp") After, as we are acquainted with strings and character arrays in C ++, look at the most common functions for working with them. The lesson will be fully built in practice. We will write their own programs-analogues for the treatment of strings and parallel to the use of standard library functions cstring (string.h – in older versions). So you're about to present itself, how they work. The standard library functions cstring include:
After, as we are acquainted with strings and character arrays in C ++, look at the most common functions for working with them. The lesson will be fully built in practice. We will write their own programs-analogues for the treatment of strings and parallel to the use of standard library functions cstring (string.h – in older versions). So you're about to present itself, how they work. The standard library functions cstring include:
- strlen() – calculates the length of the string (the number of characters excluding \0);
- strcat() – it combines strings;
- strcpy() – copies the symbols of one line to the other;
- strcmp() – compares two strings together .
Это конечно не все функции, а только те, which is covered at the article.
strlen() (from the word length – length)
Our program, which will calculate the number of characters in a string:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); int amountOfSymbol = 0; // счетчик символов while (ourStr[amountOfSymbol] != '\0') { amountOfSymbol++; } cout << "Строка \"" << ourStr << "\" состоит из " << amountOfSymbol << " символов!\n\n"; return 0; } |
For counting characters in a string of uncertain length (as it enters the user), we used the loop while – strings 13 – 17. It iterates through all the cells in the array (all the characters in a string) alternately, starting with zero. When at some step loop to meet BoxourStr [amountOfSymbol], that stores symbol\0, bust loop pause symbols and increase the counter amountOfSymbol.
So the code will look like, the replacement of our code section on the functionstrlen():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char ourStr[128] = ""; // для сохранения строки cout << "Введите текст латиницей (не больше 128 символов):\n"; cin.getline(ourStr, 128); cout << "Строка \"" << ourStr << "\" состоит из " << strlen(ourStr) << " символов!\n\n"; return 0; } |
As you can see, this short code. It did not have to declare additional variables and use a loop. The output stream cout we passed into the function string – strlen(ourStr). It is suggested that the length of the string and back to the program number. As in the previous code-analog, symbol \0 not included in the total number of characters.
The result is the program in the first and second similar:
 in C++")
strcat() (from the word concatenation – connection)
Program, which at the end of one string, appends the second string. In other words – concatenates two strings.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1- \"" << someText1 << "\" \n"; cout << "Строка someText2- \"" << someText2 << "\" \n\n"; int count1 = 0; // для индекса ячейки где хранится '\0' первой строки while (someText1[count1] != 0) { count1++; // ищем конец первой строки } int count2 = 0; // для прохода по символам второй строки начиная с 0-й ячейки while (someText2[count2] != 0) { // дописываем вконец первой строки символы второй строки someText1[count1] = someText2[count2]; count1++; count2++; } cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
By the comments in the code should be clear. Below, we write a program to perform the same actions, but using strcat(). In this feature, we will give two arguments (two strings) – strcat(someText1, someText2); . The function adds a stringsomeText2 to linesomeText1. At the same symbol '�' at the end someText1It will overwrite the first charactersomeText2. She also adds a final '�'
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сайт purecodecpp.com!"; char someText2[] = "Учите С++ c нами!"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcat(someText1 , someText2); // передаём someText2 в функцию cout << "Строка someText1 после объединения с someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Realization of unification of two strings, using standard function, took one string of code in a program – 14--s a string.
Result:

What should pay attention to the first and second code– size of the first character of the array should be sufficient for the second array of characters premises. If the size is insufficient – may occur abnormal program termination, since the string recording out of memory, which occupies the first array. For example:
1 2 | char someText1[22] = "Сайт purecodecpp.com!"; strcat(someText1, "Учите С++ c нами!"); |
In this case, a string constant“Learn C ++ c us!” It may not be written into the arraysomeText1. As there is not enough space, for such operations.
If you are using a recent version of Microsoft Visual Studio development environment, you may experience the following error:: “error C4996: ‘strcat’: This function or variable may be unsafe. Consider using strcat_s instead. To disable deprecation, use _CRT_SECURE_NO_WARNINGS. See online help for details.” This is because, that has developed a new, more secure version of the functionstrcat – this isstrcat_s.
She cares about, to avoid buffer overflow (a character array, which produced record second string). Environment offers to use the new feature, instead of outdated. Read more about this can be on the msdn website. This error can appear, if you use the functionstrcpy, which will be discussed below.
strcpy() (from the word copy – copying)
Implement copying one string and its insertion in the place of another string.
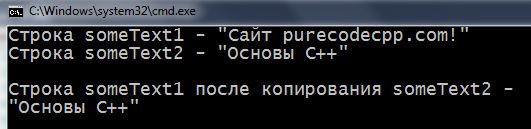
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int count = 0; while (true) // запускаем бесконечный цикл { someText1[count] = someText2[count]; // копируем посимвольно if (someText2[count] == '\0') // если нашли \0 у второй строки { break; // прерываем цикл } count++; } cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Apply the standard function librarycstring:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[64] = "Сaйт purecodecpp.com!"; char someText2[] = "Основы С++"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; strcpy(someText1, someText2); // передаём someText1 и someText2 в функцию cout << "Строка someText1 после копирования someText2 -\n\"" << someText1 << "\" \n\n"; return 0; } |
Try to compile and first, and a second program. You will see this result:
strcmp() (from the word compare – comparison)
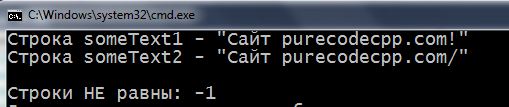
This function is designed to: she compares the two C-string character by character. If the strings are identical (and symbols and their number) – the function returns to the program number 0. If the first line is longer than a second – returns to the program number 1, and if less, then -1. The number of -1 back then, when the length of the strings is, but the characters of the strings do not match.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 | #include <iostream> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; int compare = 0; // для сравнения длины строк int count = 0; while (true) { if (strlen(someText1) < strlen(someText2)) { cout << "Строки НЕ равны: " << --compare << endl; break; } else if (strlen(someText1) > strlen(someText2)) { cout << "Строки НЕ равны: " << ++compare << endl; break; } else // если по количеству символов строки равны { if (someText1[count] == someText2[count]) // сравниваем посимвольно включая \0 { count++; if (someText1[count] == '\0' && someText2[count] == '\0') { cout << "Строки равны: " << compare << endl; break; } } else // если все же где-то встретится отличный символ { cout << "Строки НЕ равны: " << --compare << endl; break; } } } return 0; } |
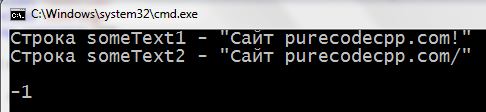
 program withstrcmp():
program withstrcmp():
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | #include <iostream> #include <cstring> using namespace std; int main() { setlocale(LC_ALL, "rus"); char someText1[] = "Сaйт purecodecpp.com!"; char someText2[] = "Сaйт purecodecpp.com/"; cout << "Строка someText1 - \"" << someText1 << "\" \n"; cout << "Строка someText2 - \"" << someText2 << "\" \n\n"; cout << strcmp(someText1, someText2) << endl << endl; return 0; } |
Share on social networks our articles with your friends, who also learn the basics of programming in C ++.
while (true) // запускаем бесконечный цикл
{
someText1[count] = someText2[count]; // copy one character
if (someText2[count] == ‘�’) // если нашли \0 у второй строки
{
break; // прерываем цикл
}
count ;
}
I do not understand what happened to the rest of the line “Сaйт purecodecpp.com!” ,
if the idea should happen: Basics With ++ pp.com.
We copy one character fewer rows in a large, so why residue someText1 removed?
because, that we copy in no less great, and the second in the first. And when suitable ' 0’ in the second row it is also overwritten in the first array. Further, when the first array will be read, then this will show zero and the end of the line, and it does not matter, there was written for him. This will be the end of the line.
#include
#include
using namespace std;
int main()
{
setlocale(LC_ALL, “rus”);
char string_Array_1[] = “Vasya, what are you, weary?”;
char string_Array_2[] = “Vasya, what are you, weary!”;
cout << "Первая строка – \"" << string_Array_1 << "\"\n";
cout << "Вторая строка – \"" << string_Array_2 << "\"\n";
cout << "=====================================================\n\n";
cout << "Если строки идентичны и по символам и по количеству, then: 0\n";
cout << "Если первая строка длиннее второй, then: +1\n";
cout << "Если первая строка короче второй, then: -1\n";
cout << "Если длина строк равна, but the characters do not match, then: -1\n";
cout << "=====================================================\n\n";
cout << "В приведенном случае получился ответ: " << strcmp(string_Array_1 , string_Array_2);
cout << endl << endl;
return 0;
}
turn out:
First line – "Вася, what are you, weary?"
The second line – "Вася, what are you, weary!"
==========================================================
If the strings are identical and the symbols and the number of, then: 0
If the first line is longer than a second, then: +1
If the first line is shorter than a second, then: -1
If the row length is, but the characters do not match, then: -1
===========================================================
In this case, I get answers: 1
I can not understand, why 1, If at the end of rows different characters: ? and !
Interesting bug in the code.
I copied, made two similar text “Vasya, what are you, weary!” в char string_Array_1[] и char string_Array_2[] and checked:
1. While the strings are the same all GOOD!!!
2. If the first line to make it get longer ” -1 ” (inverted).
3. If the first line to make it get shorter ” 1 ” (inverted).
more interesting.
4. If the first line in the word ” weary ” letter ” in ” change to ” t ” I get ” -1 ”
5. If the first line in the word ” weary ” letter ” in ” change to ” f ” I get ” 1 ”
6. If the second line in the word ” weary ” letter ” in ” change to ” t ” I get ” 1 ”
7. If the second line in the word ” weary ” letter ” in ” change to ” t ” I get ” -1 ”
Word ” weary ” I took as an example. letter ” in ” I changed to the previous and next in the alphabet. It works with any replacement of letters ( ” and ” and ” I ” I could not change).
This is not a bug (as I thought). This is due to ASCII encoding. ASCII character set can be very zaguglit. So it turns out that “in” More on this encoding “t” and less “f”
It turns out, what '?’ longer than '!’
This is true???
The more characters in ASCII code table of the “longer”.
“B” longer “A”, and “D” longer “B”.
Punctuation is also a concern.
IN “!” code 33, in “?” code 63, so ? > !
Yes, little understood, I understood (I guessed) that here there is a peg to the ASCII